🔥 GPU基础知识:从硬件架构到AI计算
GPU 是大模型时代的”发动机”——训练一个千亿参数的 LLM 可能需要数千块 GPU 运行数月,而推理服务的吞吐量和延迟也直接取决于 GPU 的利用效率。对于 AI Infra 工程师来说,理解 GPU 不是选修课,而是所有后续优化(算子、并行、调度)的硬件基础。
本文将从最基本的问题出发——GPU 为什么适合 AI 计算?它内部长什么样?程序是如何在上面运行的?——帮你建立一套完整的 GPU 认知框架。
📑 目录
- 1. CPU vs GPU:为什么深度学习选择了 GPU
- 2. GPU 硬件架构剖析
- 3. 显存层次与带宽
- 4. Tensor Core:AI 加速的核心引擎
- 5. CUDA 编程模型
- 6. GPU 关键性能指标
- 7. 主流 AI GPU 横向对比
- 8. 显存管理:AI Infra 的核心挑战
- 9. 多卡互联:从单机到集群
- 总结
- 自我检验清单
- 参考资料
1. CPU vs GPU:为什么深度学习选择了 GPU
要理解 GPU 的价值,最好的方式是把它和 CPU 放在一起对比。
想象你要批改 10000 份选择题试卷。CPU 的做法是请一位经验丰富的阅卷老师,他速度快、能处理各种复杂题型,但一次只能改一份;GPU 的做法是请 10000 个临时工,每人只会对答案这一件事,但所有人同时开工——1 秒就全部改完了。
这就是 延迟导向(Latency-oriented)与 吞吐导向(Throughput-oriented)的核心区别。
1.1 架构哲学的根本差异
| 📊 对比维度 | CPU | GPU |
|---|---|---|
| 设计目标 | 低延迟处理复杂任务 | 高吞吐处理大量简单任务 |
| 核心数量 | 几个到几十个”大核” | 数千到上万个”小核” |
| 单核能力 | 强(复杂分支预测、乱序执行) | 弱(简单 ALU,按序执行) |
| 缓存占比 | 芯片面积的大部分 | 芯片面积的小部分 |
| 控制逻辑 | 复杂(乱序执行、分支预测器) | 简单(大量核心共享控制单元) |
| 内存带宽 | 较低(DDR5 ~100 GB/s) | 极高(HBM3 ~3 TB/s) |
| 适合任务 | 串行逻辑、操作系统、网络服务 | 矩阵运算、数据并行、图形渲染 |
1.2 深度学习为什么天然适合 GPU
深度学习的计算核心是什么?拆到最底层,就是海量的矩阵乘法和逐元素运算:
- 前向传播:每一层都是 $Y = XW + b$,本质是矩阵乘法
- 反向传播:计算梯度依然是矩阵乘法($\frac{\partial L}{\partial W} = X^\top \cdot \frac{\partial L}{\partial Y}$)
- Attention 计算:$\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V$,核心还是矩阵乘法
这些运算有两个关键特征:
- 数据并行度极高:矩阵中每个元素的计算相互独立,天然可以分配给不同的计算核心
- 计算模式规则:不需要复杂的分支判断,所有线程执行相同的指令
这恰好是 GPU 的长项——用成千上万个简单核心同时处理,吞吐量远超 CPU。
💡 提示:一块 H100 GPU 的 FP16 算力约为 989 TFLOPS,而高端服务器 CPU(如 Intel Xeon w9-3595X)的 FP16 算力通常在个位数 TFLOPS 级别。差距在两个数量级以上。
2. GPU 硬件架构剖析
了解了 GPU “为什么快”之后,我们来看看它”内部长什么样”。以 NVIDIA GPU 为例,从外到内可以分为三个层次:
2.1 GPC → TPC → SM 的层级结构

NVIDIA GPU 的计算核心按层级组织,就像一家大公司的组织架构:
1 | GPU 芯片 |
2.2 SM:GPU 的基本调度单元
SM(Streaming Multiprocessor)是理解 GPU 架构的关键,所有的线程调度和执行都发生在 SM 层面。
以 H100 的 SM 为例,每个 SM 内部包含:
| 🔧 组件 | 数量 | 功能 |
|---|---|---|
| CUDA Core(FP32) | 128 | 执行浮点和整数运算 |
| Tensor Core(第四代) | 4 | 执行矩阵乘累加(MMA)运算 |
| Load/Store Unit | 32 | 负责内存读写 |
| SFU | 16 | 执行超越函数(sin、cos、exp 等) |
| Warp Scheduler | 4 | 每周期调度 4 个 Warp |
| Register File | 256 KB | 线程私有寄存器 |
| Shared Memory / L1 Cache | 228 KB(可配置) | SM 内共享的高速存储 |
📌 关键点:SM 是资源分配的最小粒度。当你编写 CUDA Kernel 时,一个 Thread Block 会被调度到一个 SM 上执行。SM 内的寄存器、共享内存等资源由这个 SM 上的所有 Thread Block 共同分配。
2.3 Warp:GPU 执行的最小单位
GPU 不是一个线程一个线程执行的,而是以 Warp(线程束)为单位,32 个线程锁步执行同一条指令。这就像军队齐步走——32 个士兵听同一声号令,迈出同一只脚。
1 | Warp(32 个线程) |
这种执行模式叫做 SIMT(Single Instruction, Multiple Threads),是 NVIDIA 对 SIMD 的扩展。
⚠️ 注意:如果 Warp 内的线程遇到分支(if-else),走不同分支的线程会被 掩码(mask),导致部分线程空转。这就是所谓的 Warp Divergence,是 GPU 编程中需要极力避免的性能杀手。
3. 显存层次与带宽
GPU 的计算再快,如果数据”喂”不上来也白搭。在 AI 工作负载中,显存带宽往往比算力更先成为瓶颈——这就是为什么 AI Infra 领域有句话叫 “Memory is the new compute"。
3.1 GPU 存储层级金字塔
GPU 的存储层级和 CPU 类似,越靠近计算核心速度越快、容量越小:
| 📊 层级 | 容量 | 带宽/延迟 | 作用域 | 说明 |
|---|---|---|---|---|
| Register(寄存器) | 每线程 ~255 个 | ~0 cycle | 单线程私有 | 最快,但容量极有限 |
| Shared Memory | 每 SM ~228 KB | ~30 cycle | SM 内所有线程 | 程序员显式管理的”L1 级别”缓存 |
| L1 Cache | 与 Shared Memory 共享 | ~30 cycle | SM 内 | 硬件自动管理 |
| L2 Cache | 整卡 ~50 MB | ~200 cycle | 全局 | 所有 SM 共享 |
| HBM(显存) | 80 GB | ~600 cycle | 全局 | 主存储,带宽决定吞吐上限 |
3.2 HBM:高带宽显存
传统 GDDR 显存就像一条单车道公路——传输速率有限。HBM(High Bandwidth Memory)则是把几千条车道堆叠在一起,通过硅中介层(Silicon Interposer)直接和 GPU 芯片互联,实现数倍的带宽提升。
| 📊 显存类型 | 代表 GPU | 带宽 | 容量 |
|---|---|---|---|
| GDDR6X | RTX 4090 | 1,008 GB/s | 24 GB |
| HBM2e | A100 | 2,039 GB/s | 80 GB |
| HBM3 | H100 | 3,350 GB/s | 80 GB |
| HBM3e | B200 | 8,000 GB/s | 192 GB |
💡 提示:从 A100 到 B200,显存带宽增长了近 4 倍。这对 LLM 推理意义重大——推理阶段的 decode 是典型的 Memory-bound 任务,带宽每提升 1 倍,理论吞吐量就能接近翻倍。
3.3 Roofline 模型:算力 vs 带宽的平衡点
判断一个计算任务是 Compute-bound(受算力限制)还是 Memory-bound(受带宽限制),可以用 算术强度(Arithmetic Intensity)这个指标:
$$
\text{算术强度} = \frac{\text{浮点运算量 (FLOPs)}}{\text{内存访问量 (Bytes)}}
$$
当算术强度低于 GPU 的 ops:byte 比(即算力 / 带宽)时,任务是 Memory-bound;反之是 Compute-bound。
以 H100 SXM 为例:
- FP16 算力:989 TFLOPS
- HBM3 带宽:3,350 GB/s
- ops:byte 比 = $\frac{989 \times 10^{12}}{3,350 \times 10^9} \approx 295$ FLOPs/Byte
这意味着:如果你的 Kernel 每从显存读取 1 Byte 数据,需要执行至少 295 次 FP16 浮点运算才能让算力充分跑满。否则 GPU 会”闲着等数据”。
Roofline 模型是一张对数坐标图,横轴是算术强度(Arithmetic Intensity),纵轴是性能(FLOP/s),用来判断一个程序是”内存瓶颈”还是”计算瓶颈”。看懂它只需要理解三条线和一个点。
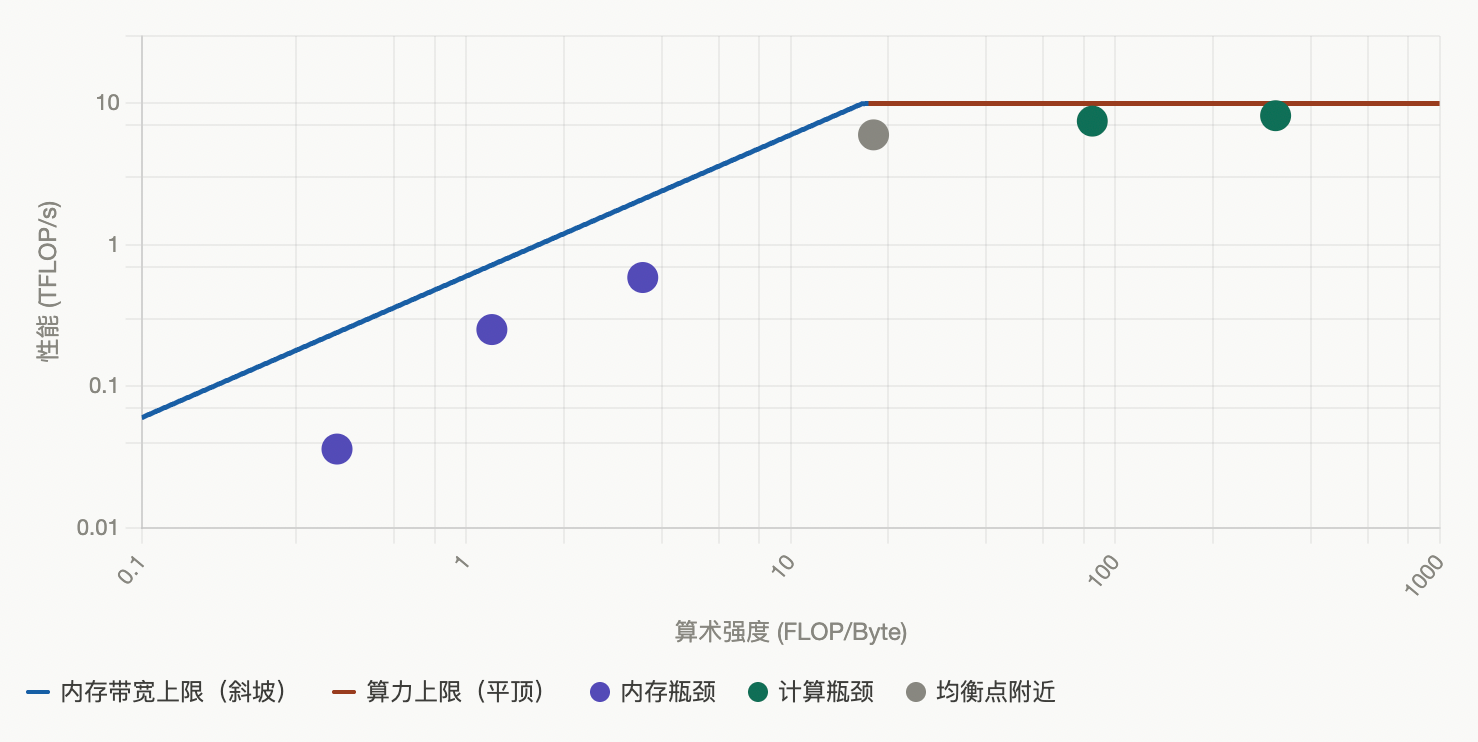
怎么看这张图(三个核心要素)
- 斜坡(蓝色)= 内存带宽上限,斜率 = 峰值带宽(GB/s)。在斜坡区域,性能由内存带宽决定:数据读不够快,计算单元在等待。
- 平顶(红色)= 算力上限,水平线 = 峰值算力(TFLOP/s)。在平顶区域,内存够快,但计算单元已跑满。
- 脊点(Ridge point)= 分界线,斜坡与平顶的交叉点,对应的算术强度 = 峰值算力 ÷ 峰值带宽。左边内存瓶颈,右边计算瓶颈。
📌 关键点:大多数深度学习算子(尤其是 Attention、LayerNorm、激活函数等)的算术强度远低于 295,这就是为什么 FlashAttention、Kernel Fusion 等优化技术如此重要——它们的核心思路就是减少显存访问、提升算术强度。
4. Tensor Core:AI 加速的核心引擎
CUDA Core 是通用计算核心,一个时钟周期执行一次 FMA(fused multiply-add)运算。而 Tensor Core 是专门为矩阵运算设计的加速单元——一个时钟周期可以完成一个小矩阵的乘累加运算。
4.1 工作原理
Tensor Core 执行的基本操作是 矩阵乘累加(MMA, Matrix Multiply-Accumulate):
$$
D = A \times B + C
$$
其中 $A$、$B$、$C$、$D$ 是小尺寸矩阵(具体尺寸取决于精度和架构代次)。
以 Hopper 架构为例,单个 Tensor Core 一个时钟周期可以完成 $16 \times 8 \times 16$ 的 FP16 矩阵乘累加——相当于一个 CUDA Core 要执行数千个时钟周期的工作量。16×8×16 是什么意思?这是一次矩阵乘累加(MMA)的操作维度:
- 矩阵 A:形状 16 × 16,FP16
- 矩阵 B:形状 16 × 8,FP16
- 矩阵 C(累加目标):形状 16 × 8,FP32
- 即在一个时钟周期内完成:C += A × B
4.2 精度格式演进
不同精度格式在算力、精度、显存占用之间做了不同的取舍:
| 📊 精度 | 位宽 | 动态范围 | 首次 Tensor Core 支持 | 典型应用 |
|---|---|---|---|---|
| FP32 | 32 bit | 高 | — | 基准精度、loss 累加 |
| TF32 | 19 bit | 同 FP32 | Ampere(A100) | 训练(Ampere 上的默认 FP32 路径) |
| FP16 | 16 bit | 较窄 | Volta(V100) | 混合精度训练(需 loss scaling) |
| BF16 | 16 bit | 同 FP32 | Ampere(A100) | 混合精度训练(推荐,无需 loss scaling) |
| FP8(E4M3/E5M2) | 8 bit | 可选 | Hopper(H100) | 训练 + 推理 |
| INT8 | 8 bit | 整数 | Turing(T4) | 推理量化 |
| FP4 | 4 bit | 极窄 | Blackwell(B200) | 推理量化 |
💡 提示:BF16 和 FP16 都是 16 位,但 BF16 保留了和 FP32 相同的 8 位指数位,因此动态范围更大,训练时更不容易溢出。现代大模型训练几乎都用 BF16 而非 FP16。
4.3 Tensor Core 的算力倍增
Tensor Core 对比 CUDA Core 的性能提升非常显著(以 H100 SXM 为例):
| 📊 精度 | CUDA Core 算力 | Tensor Core 算力 | 加速比 |
|---|---|---|---|
| FP32 | 67 TFLOPS | 495 TFLOPS(TF32) | ~7.4× |
| FP16 | 134 TFLOPS | 989 TFLOPS | ~7.4× |
| FP8 | — | 1,979 TFLOPS | — |
📌 关键点:要触发 Tensor Core 加速,矩阵的维度必须满足对齐要求(通常是 8 或 16 的倍数)。在实际工程中,如果模型的 hidden_size 不是 8 的倍数,Tensor Core 可能无法被充分利用。
5. CUDA 编程模型
CUDA 是 NVIDIA 提供的并行计算编程框架,是连接”软件算法”和”硬件执行”的桥梁。即使你日常用 PyTorch 而不直接写 CUDA,理解它的编程模型也有助于理解底层发生了什么。
5.1 线程层级:Grid → Block → Thread
CUDA 程序以 Kernel 为单位在 GPU 上执行。Kernel 的线程按三级层次组织:
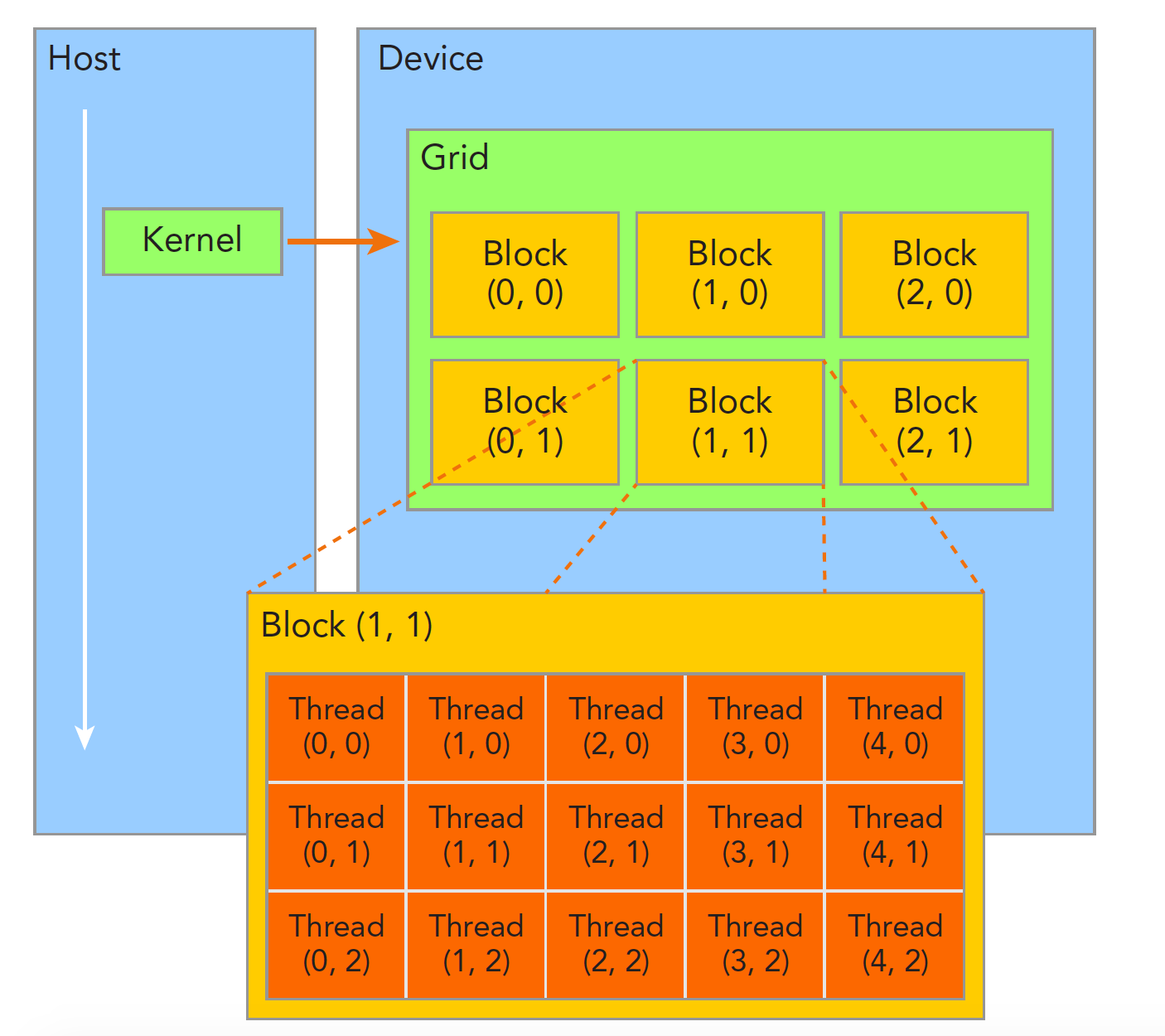
| 📊 层级 | 说明 | 硬件对应 |
|---|---|---|
| Grid | 一次 Kernel 启动的所有线程 | 整个 GPU |
| Block(线程块) | 一组协作的线程(最多 1024 个) | 调度到一个 SM |
| Thread(线程) | 最小执行单元 | CUDA Core |
| Warp(线程束) | 32 个连续线程(隐式分组) | SM 中的 Warp Scheduler |
5.2 一个简单的 CUDA Kernel 示例
下面是一个向量加法的 CUDA Kernel,展示 CUDA 的基本编程范式:
1 | // 向量加法 Kernel:C[i] = A[i] + B[i] |
执行流程:📥 Host 分配显存并拷贝数据 → ⚙️ 启动 Kernel,GPU 将 Block 分配到各 SM → 📤 Kernel 执行完毕,结果拷回 Host。
5.3 内存模型与存储对应
CUDA 编程中不同的变量声明对应不同的硬件存储:
| 📊 CUDA 内存类型 | 声明方式 | 硬件位置 | 作用域 | 生命周期 |
|---|---|---|---|---|
| Register | 局部变量 | SM 寄存器堆 | 单线程 | Kernel |
| Local Memory | 溢出的局部变量 | HBM(显存) | 单线程 | Kernel |
| Shared Memory | __shared__ |
SM 片上存储 | Block 内 | Kernel |
| Global Memory | __device__ / cudaMalloc |
HBM(显存) | 所有线程 | 应用 |
| Constant Memory | __constant__ |
HBM + 缓存 | 所有线程 | 应用 |
⚠️ 注意:Local Memory 虽然名字里有”Local”,但实际存储在 HBM 上,访问速度和 Global Memory 一样慢。当寄存器不够用时,编译器会自动将变量溢出到 Local Memory,这叫做 Register Spilling,是需要警惕的性能问题。
5.4 用 PyTorch 感受 GPU 计算
大多数 AI Infra 工程师日常并不直接写 CUDA C,而是通过 PyTorch 等框架间接调用。理解底层 CUDA 有助于写出更高效的 PyTorch 代码:
1 | import torch |
6. GPU 关键性能指标
评估一块 GPU 的 AI 计算能力,需要关注以下核心指标:
6.1 四大核心指标
| 📊 指标 | 含义 | 为什么重要 |
|---|---|---|
| 算力(TFLOPS) | 每秒浮点运算次数 | 决定 Compute-bound 任务的上限 |
| 显存带宽(GB/s) | 每秒显存读写数据量 | 决定 Memory-bound 任务的上限 |
| 显存容量(GB) | 可存储的数据总量 | 决定能跑多大的模型 |
| 互联带宽(GB/s) | GPU 间通信速度 | 决定多卡并行的扩展效率 |
6.2 算力计算公式
GPU 的理论峰值算力可以通过硬件参数推算:
$$
\text{FP16 算力} = \text{SM 数量} \times \text{每 SM 的 FP16 Core 数} \times 2 \times \text{时钟频率}
$$
其中 $\times 2$ 是因为每个 FP Core 每周期执行一次 FMA(Fused Multiply-Add),包含一次乘法和一次加法。
Tensor Core 的算力计算方式不同,需要考虑每个 Tensor Core 每周期完成的 MMA 运算规模。
💡 提示:厂商标称的 TFLOPS 通常是带 Tensor Core 的稀疏(Sparsity)模式峰值,实际应用中的有效算力通常只有峰值的 30%~60%。当你做性能分析时,应该用实测值而非标称值。
7. 主流 AI GPU 横向对比
下面是截至 2025 年主流 NVIDIA AI GPU 的核心参数对比:
| 📊 型号 | 架构 | SM 数 | 显存 | 带宽 | FP16 算力 | FP8 算力 | TDP | 典型用途 |
|---|---|---|---|---|---|---|---|---|
| V100 | Volta | 80 | 32 GB HBM2 | 900 GB/s | 125 TFLOPS | — | 300W | 经典训练卡 |
| A100 SXM | Ampere | 108 | 80 GB HBM2e | 2,039 GB/s | 312 TFLOPS | — | 400W | 训练 + 推理 |
| H100 SXM | Hopper | 132 | 80 GB HBM3 | 3,350 GB/s | 989 TFLOPS | 1,979 TFLOPS | 700W | 大规模训练 |
| H200 | Hopper | 132 | 141 GB HBM3e | 4,800 GB/s | 989 TFLOPS | 1,979 TFLOPS | 700W | 长序列推理 |
| B200 | Blackwell | 160 | 192 GB HBM3e | 8,000 GB/s | 2,250 TFLOPS | 4,500 TFLOPS | 1000W | 下一代旗舰 |
| L40S | Ada | 142 | 48 GB GDDR6 | 864 GB/s | 366 TFLOPS | — | 350W | 推理 / 多媒体 |
⚠️ 注意:同一架构可能有 SXM 和 PCIe 两种封装。SXM 版本通常功耗更高、频率更高、且支持 NVLink 互联,性能显著强于 PCIe 版本。选型时务必确认封装类型。
8. 显存管理:AI Infra 的核心挑战
训练大模型时,显存往往是最先遇到的瓶颈。一个 7B 参数的模型(FP16),仅模型参数就需要约 14 GB 显存;加上优化器状态、梯度、激活值,实际显存占用可达 4~8 倍参数量。
8.1 训练时显存都用在哪里
以 Adam 优化器 + FP16 混合精度训练为例,每个参数需要的显存:
| 📊 组成部分 | 每参数字节 | 说明 |
|---|---|---|
| FP16 参数 | 2 B | 前向 / 反向计算使用 |
| FP32 参数副本 | 4 B | Adam 需要维护 FP32 master weights |
| FP32 梯度 | 4 B | 反向传播产生 |
| Adam 一阶动量(m) | 4 B | 梯度的指数移动平均 |
| Adam 二阶动量(v) | 4 B | 梯度平方的指数移动平均 |
| 合计 | 18 B | — |
一个 7B 模型的固定显存 = $7 \times 10^9 \times 18 = 126$ GB,这还不算激活值(Activation)。
8.2 常用显存优化策略
面对显存不够用的困境,AI Infra 领域发展出了一系列经典策略:
| 📊 策略 | 原理 | 显存节省 | 代价 |
|---|---|---|---|
| 混合精度训练 | 用 FP16/BF16 做前向反向,FP32 做参数更新 | ~50% 参数显存 | 需要 loss scaling(FP16) |
| 梯度累积 | 用多个 micro-batch 累积梯度,等效大 batch | 减少激活值峰值 | 增加训练步数 |
| 梯度检查点 | 前向时只保留部分激活,反向时重新计算 | 激活显存降至 $O(\sqrt{N})$ | 增加约 33% 计算量 |
| ZeRO 优化 | 将优化器状态 / 梯度 / 参数分片到多卡 | 线性降低每卡显存 | 增加通信量 |
| Offloading | 将部分数据卸载到 CPU 内存或 NVMe | 突破单卡显存上限 | PCIe 带宽成为瓶颈 |
💡 提示:这些策略并非互斥,实践中通常组合使用。例如 DeepSpeed ZeRO Stage 2 + 混合精度 + 梯度检查点是训练中大模型(7B~70B)的常见配置。
9. 多卡互联:从单机到集群
当单卡显存和算力无法满足需求时,就需要多卡并行。GPU 之间的互联带宽和拓扑直接决定了并行训练的效率。
9.1 互联技术对比
| 📊 互联技术 | 带宽 | 场景 | 说明 |
|---|---|---|---|
| PCIe 5.0 | 128 GB/s(双向) | 跨卡(通用) | 普遍但带宽较低 |
| NVLink 4.0(Hopper) | 900 GB/s(全双工) | 机内 GPU 互联 | 专用高速互联,H100 使用 |
| NVLink 5.0(Blackwell) | 1,800 GB/s(全双工) | 机内 GPU 互联 | B200 使用 |
| NVSwitch | 连接所有 NVLink | 机内全互联 | 实现 All-to-All 全带宽通信 |
| InfiniBand NDR | 400 Gb/s(50 GB/s) | 跨机互联 | 大规模集群标配 |
9.2 典型多卡拓扑
以 DGX H100(8 卡)为例:
- 8 块 H100 通过 NVSwitch 实现全互联,任意两卡之间 900 GB/s
- 每台机器通过 8 张 ConnectX-7 InfiniBand 网卡与集群相连
- 机内通信 >> 机间通信,这个带宽差异直接影响并行策略的选择
📌 关键点:在设计分布式训练策略时,应该让通信量大的并行维度(如张量并行)放在高带宽的机内 NVLink 上,通信量相对较小的并行维度(如数据并行、流水线并行)放在机间 InfiniBand 上。
1 | # 查看 GPU 拓扑信息 |
📝 总结
本文从 CPU 与 GPU 的架构差异出发,逐步深入到 GPU 的内部结构,涵盖了以下核心知识点:
- 为什么选择 GPU:深度学习的矩阵运算天然适合 GPU 的大规模并行架构
- 硬件架构:GPC → TPC → SM → CUDA Core / Tensor Core 的层级组织,Warp 是执行的最小调度单位
- 显存层次:Register → Shared Memory → L1/L2 Cache → HBM 的金字塔结构,带宽往往比算力更先成为瓶颈
- Tensor Core:专为矩阵乘累加设计的加速单元,BF16/FP8 等低精度格式持续推动算力增长
- CUDA 编程模型:Grid → Block → Thread 的线程组织,以及存储类型与硬件的对应关系
- 性能评估:算力、带宽、显存容量、互联带宽四大核心指标
- 显存管理:混合精度、梯度累积、梯度检查点、ZeRO 等经典优化策略
- 多卡互联:NVLink、NVSwitch、InfiniBand 构成从机内到集群的通信基础
掌握这些基础知识后,你将具备阅读后续 CUDA 编程、分布式训练、推理优化等进阶文章的硬件认知基础。
🎯 自我检验清单
- 能说出 CPU 和 GPU 在架构设计哲学上的核心区别
- 能画出 GPU 的层级结构(GPC → SM → CUDA Core / Tensor Core)
- 能解释 Warp 的概念以及 Warp Divergence 为什么影响性能
- 能说出 GPU 存储层级(Register → Shared Memory → L2 → HBM)各自的容量和速度量级
- 能用 Roofline 模型判断一个算子是 Compute-bound 还是 Memory-bound
- 能解释 BF16 和 FP16 的区别,以及为什么大模型训练更推荐 BF16
- 能列举 3 种以上显存优化策略及其原理
- 能用
nvidia-smi查看 GPU 状态、拓扑信息 - 能说出 NVLink 和 PCIe 在带宽上的数量级差异
- 能估算一个 7B 参数模型使用 Adam + FP16 混合精度训练时的显存占用
📚 参考资料
- NVIDIA CUDA C++ Programming Guide
- NVIDIA H100 Tensor Core GPU Architecture Whitepaper
- NVIDIA A100 Tensor Core GPU Architecture Whitepaper
- NVIDIA Blackwell Architecture Whitepaper
- Mixed Precision Training - NVIDIA Developer Blog
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
- Roofline: An Insightful Visual Performance Model