1.3 CUDA 内存模型
理解 CUDA 的多层内存层次是写出高性能 Kernel 的关键。本文详解全局内存、共享内存、寄存器、常量内存和统一内存的特性、适用场景及优化技巧。
📑 目录
1. 为什么内存模型如此重要
GPU 的计算能力极强——一块 A100 的峰值算力为 312 TFLOPS(FP16,Tensor Core 含稀疏加速),但它的显存带宽只有约 2 TB/s。做一道简单的算术:一次浮点乘加(FMA)需要读 2 个 float(8 Bytes)产生 2 个 FLOP,那么 2 TB/s 带宽最多喂饱 500 GFLOPS 的计算——不到峰值算力的 0.2%。
这意味着:绝大多数 Kernel 的性能瓶颈不是计算,而是内存访问。理解 CUDA 的多层内存层次,学会把数据放在”离计算最近的地方”,是优化 GPU 程序的第一课。
2. 内存层次总览
GPU 的内存层次就像城市的交通系统——寄存器是办公桌上的文件(最快但最小),共享内存是同一办公室的文件柜(快速且可共享),全局内存是城市外的大仓库(容量大但来回需要时间)。
2.1 内存层次架构图
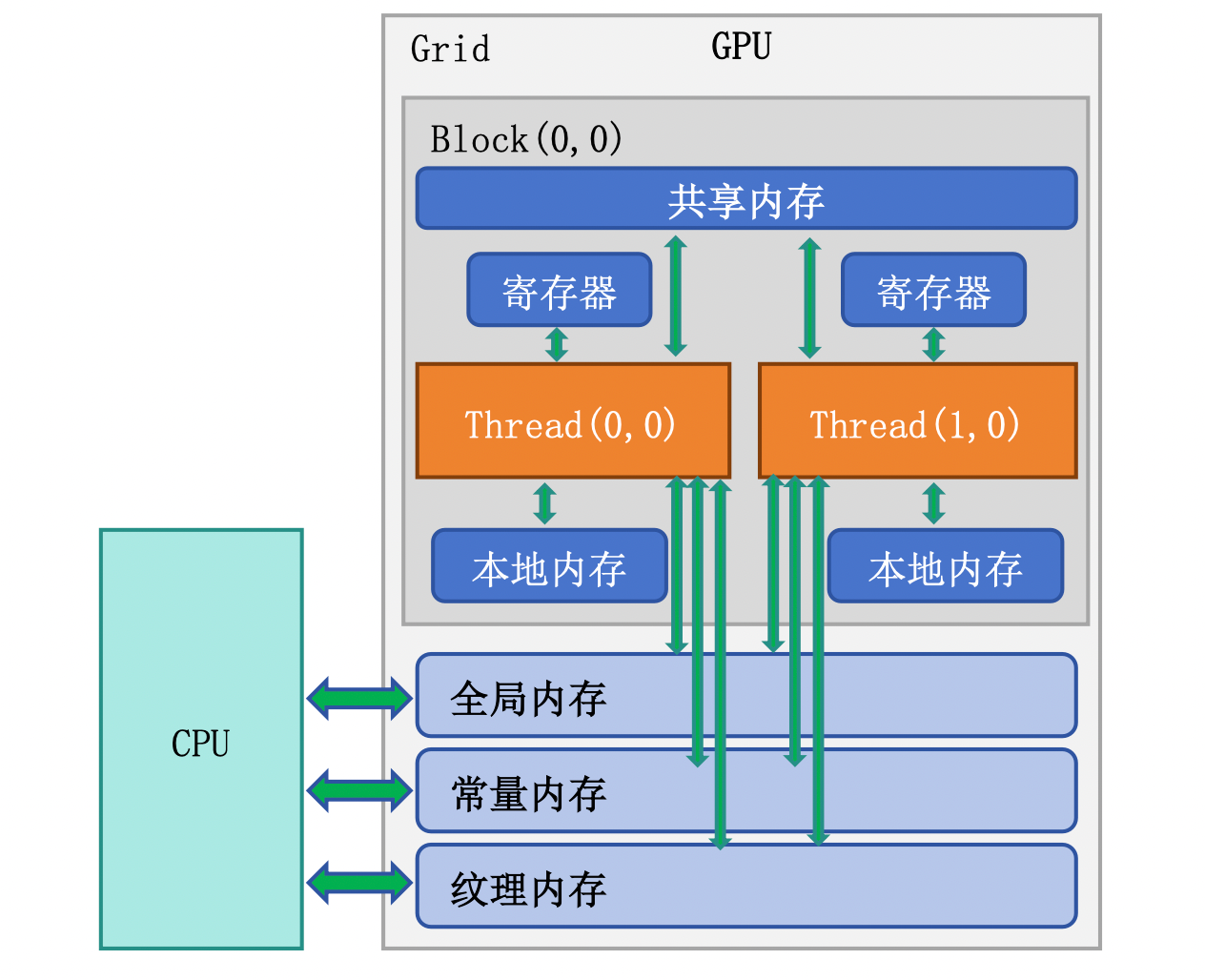
graph TD
A["线程 (Thread)"] --> B["寄存器 (Registers)"]
A --> C["局部内存 (Local Memory)"]
D["线程块 (Block)"] --> E["共享内存 (Shared Memory)"]
F["Grid (所有线程)"] --> G["全局内存 (Global Memory)"]
F --> H["常量内存 (Constant Memory)"]
F --> I["纹理内存 (Texture Memory)"]
2.2 各级内存对比
| 📊 内存类型 | 位置 | 容量 | 延迟 | 带宽 | 作用域 | 生命周期 |
|---|---|---|---|---|---|---|
| 寄存器 | SM 芯片上 | ~256KB/SM | 1 cycle | 最高 | 单线程 | 线程生命周期 |
| 共享内存 | SM 芯片上 | 48~228KB/SM(因架构而异) | ~20 cycles | ~19 TB/s | Block 内 | Block 生命周期 |
| L1 Cache | SM 芯片上 | 128~256KB/SM | ~30 cycles | ~19 TB/s | 自动 | 自动管理 |
| L2 Cache | GPU 芯片上 | 6~50MB | ~200 cycles | ~5 TB/s | 所有 SM | 自动管理 |
| 全局内存 (HBM) | 芯片外 | 16~80GB | ~400 cycles | 1~3.4 TB/s | 全局 | 应用生命周期 |
| 常量内存 | 芯片外+缓存 | 64KB | 1~400 cycles | 有缓存时极高 | 全局只读 | 应用生命周期 |
3. 全局内存
全局内存(Global Memory)是 GPU 的”主存”,对应物理上的 HBM(高带宽内存)。它容量最大但延迟最高,是 CPU-GPU 数据交换的枢纽。
3.1 基本操作
1 | // 分配设备内存 |
3.2 合并访问(Coalesced Access)
全局内存的访问效率取决于一个 Warp 内 32 个线程的访问模式是否连续对齐。GPU 以 32B/64B/128B 的粒度从全局内存取数据(一次”事务”),如果 Warp 内线程访问的地址连续,一次事务就能满足所有线程——这就是合并访问。
1 | // ✅ 合并访问:连续线程访问连续地址 |
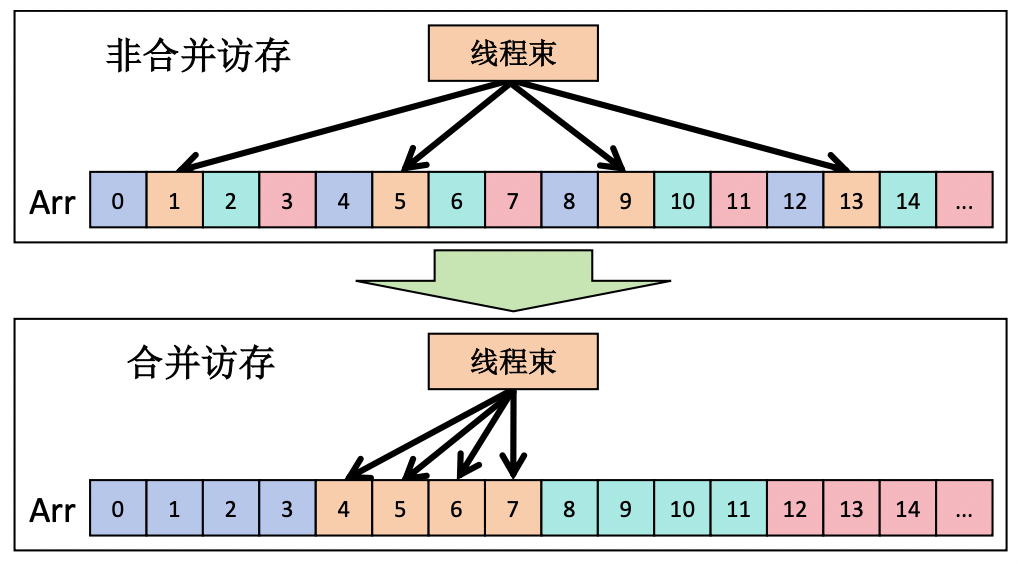
3.3 访问模式对性能的影响
| 访问模式 | 事务数(Warp 访问 32 个 float) | 有效带宽利用率 |
|---|---|---|
| 完美合并(连续对齐) | 1 次 128B 事务 | 100% |
| 连续但未对齐 | 2 次 128B 事务 | 50% |
| 随机散列访问 | 最多 32 次 32B 事务 | ~3% |
💡 提示:在设计数据结构时,优先选择 Structure of Arrays (SoA) 而非 Array of Structures (AoS),因为 SoA 更容易实现合并访问。
3.4 SoA vs AoS 示例
1 | // ❌ AoS(Array of Structures)— 相邻线程访问不连续 |
4. 共享内存
共享内存(Shared Memory)位于 SM 芯片上,48~228KB/SM(因架构而异),是 Block 内所有线程共享的高速暂存。把它想象成一个团队的白板——团队成员都可以快速读写,但其他团队看不到。
4.1 声明与使用
静态声明:
1 | __global__ void sharedMemDemo(float* input, float* output, int N) { |
动态声明:
1 | // 动态声明:运行时确定大小 |
4.2 Bank Conflict
共享内存被划分为 32 个 Bank(对应 32 个 Warp 线程),每个 Bank 宽度为 4 bytes。当一个 Warp 中多个线程同时访问同一个 Bank 的不同地址时,访问必须串行化——这就是 Bank Conflict。
1 | Bank 编号 = (地址 / 4 bytes) % 32 |
1 | // ✅ 无 Bank Conflict:每个线程访问不同 Bank |
4.3 避免 Bank Conflict 的技巧
对于矩阵转置等场景,经典方法是添加 padding:
1 | // 原始:2D 共享内存,列访问时会有 Bank Conflict |
4.4 共享内存配置
现代 GPU(sm_80+)的 L1 Cache 和共享内存共享同一块物理 SRAM,可以通过 API 配置比例:
1 | // 优先分配更多共享内存(最大 164KB on A100) |
5. 寄存器与局部内存
5.1 寄存器
寄存器是每个线程私有的最快存储。Kernel 中的局部变量默认存放在寄存器中:
1 | __global__ void compute(float* data, int N) { |
5.2 寄存器溢出(Register Spilling)
每个 SM 的寄存器总量有限(如 A100 为 65536 个 32-bit 寄存器/SM)。当一个线程使用的寄存器超过 SM 能分配给它的数量时,多出的变量会”溢出”到局部内存(实际是全局内存的一块区域,有 L1/L2 缓存加速但延迟仍然高)。
1 | # 查看 Kernel 的寄存器用量 |
5.3 寄存器使用建议
| ✅ 推荐做法 | ❌ 不推荐做法 |
|---|---|
| 复用临时变量 | 声明大量独立变量 |
循环展开适度(#pragma unroll) |
展开因子过大导致寄存器爆炸 |
用 --ptxas-options=-v 监控 |
盲目追求零溢出 |
⚠️ 注意:寄存器使用是一个权衡——用更多寄存器可以减少计算中的内存访问,但也会降低 SM 上能同时驻留的 Warp 数量(降低占用率)。需要根据具体 Kernel 找平衡点。
6. 常量内存
常量内存(Constant Memory)是一块 64KB 的只读全局内存区域,配有专用的常量缓存。当 Warp 内所有线程读取同一地址时,一次缓存读取就能广播给 32 个线程。
6.1 声明与使用
1 | // 在全局作用域声明常量内存 |
6.2 适用场景
| ✅ 适合常量内存 | ❌ 不适合常量内存 |
|---|---|
| 所有线程读相同值(卷积核、系数表) | 每个线程读不同地址 |
| 数据量 ≤ 64KB | 数据量超过 64KB |
| 数据在 Kernel 执行期间不变 | 数据需要被 GPU 修改 |
📌 关键点:如果 Warp 内不同线程访问常量内存的不同地址,访问会被串行化为 32 次读取,性能反而比全局内存更差。
7. 纹理内存
纹理内存(Texture Memory)通过专用的纹理缓存访问全局内存,它针对二维空间局部性做了优化。在深度学习时代,纹理内存使用较少,但在图像处理和某些插值场景中仍有价值。
7.1 特点
- 针对 2D 空间局部性优化的缓存策略
- 支持硬件插值(线性/双线性)
- 支持自动边界处理(Clamp/Wrap)
- 对不规则访问模式比全局内存表现更好
7.2 现代替代
在 CUDA 12+ 中,L1/L2 缓存的优化已经覆盖了大部分纹理内存的使用场景。对于新代码,建议:
- 规则访问模式 → 直接使用全局内存 + L1 缓存
- 只读数据 → 使用
__ldg()内置函数走只读缓存路径 - 需要硬件插值 → 仍然使用纹理
1 | // __ldg() 走只读缓存路径,无需配置纹理对象 |
8. 统一内存
统一内存(Unified Memory)是 CUDA 6.0 引入的编程抽象——它提供一个单一地址空间,CPU 和 GPU 都可以通过相同的指针访问数据,系统自动在两者之间迁移页面。
8.1 基本用法
1 | // 分配统一内存 |
8.2 页面迁移机制
统一内存的”魔法”背后是操作系统级别的按需页面迁移:
- CPU 首次写入时,页面驻留在系统内存
- GPU Kernel 访问时触发缺页中断,驱动将页面迁移到显存
- Kernel 执行完后 CPU 再次访问,页面迁回系统内存
8.3 性能优化:预取
自动按需迁移有延迟开销,可以通过预取(Prefetch)提前触发迁移:
1 | // 在 Kernel 启动前,预取数据到 GPU |
8.4 适用场景分析
| ✅ 适合统一内存 | ❌ 不适合统一内存 |
|---|---|
| 原型开发和快速迭代 | 极致性能要求的生产代码 |
| CPU/GPU 交替访问的复杂数据结构 | 大块数据的单向传输 |
| 链表、树等指针结构 | 简单的输入→计算→输出模式 |
| 不确定 GPU 会访问哪些数据 | 明确知道数据使用模式 |
⚠️ 注意:统一内存简化了编程但可能牺牲性能。对于性能敏感的代码,显式使用 cudaMemcpy 通常比统一内存快,因为你可以精确控制数据传输时机并与计算重叠。
9. 内存选型决策指南
面对一个新 Kernel,如何决定把数据放在哪里?
graph TD
A["数据是否在 Kernel 中被修改?"] -->|只读| B["所有线程读同一值?"]
A -->|读写| C["是否需要 Block 内共享?"]
B -->|是 且 ≤64KB| D["常量内存"]
B -->|否| E["全局内存 + __ldg()"]
C -->|是| F["共享内存"]
C -->|否| G["全局内存 (合并访问)"]
9.1 快速参考卡片
| 需求 | 首选方案 | 次选方案 |
|---|---|---|
| Block 内线程间数据交换 | 共享内存 + __syncthreads() |
Warp Shuffle(同 Warp 内) |
| 全局只读广播 | 常量内存 | __ldg() |
| 大数组逐元素处理 | 全局内存(合并访问) | — |
| 局部累加器/计数器 | 寄存器 | — |
| 复杂数据结构快速原型 | 统一内存 | — |
| 减少全局内存事务 | Tiling + 共享内存 | L1 缓存 |
9.2 典型优化模式:Tiling
Tiling 是最经典的内存优化模式——将全局内存数据分块加载到共享内存,在共享内存上做多次计算,从而用少量全局内存访问换取大量快速的共享内存访问:
1 | __global__ void matmulTiled(float* A, float* B, float* C, |
💡 提示:Tiling 的核心思想——“搬一次数据,用多次”——在 FlashAttention、GEMM 优化等高级场景中反复出现,是 GPU 编程最重要的优化范式之一。
📝 总结
CUDA 内存模型的核心认知:
- 算力远大于带宽:内存访问是大多数 Kernel 的性能瓶颈
- 层次化设计:越靠近计算单元的存储越快、越小
- 合并访问:全局内存的首要优化原则——连续线程访问连续地址
- 共享内存:Block 内协作的高速中转站,注意 Bank Conflict
- Tiling:最通用的优化范式——分块加载、本地计算、减少全局访问
- 寄存器:单线程最快存储,但有限,需权衡占用率
- 统一内存:编程简便但性能次优,适合原型和复杂数据结构
🎯 自我检验清单
- 能列出 CUDA 五种主要内存类型及其容量、延迟、作用域
- 能解释合并访问的条件,并判断给定访问模式是否合并
- 能将一个 AoS 数据结构改造为 SoA 以实现合并访问
- 能正确使用
__shared__声明共享内存并配合__syncthreads() - 能识别 Bank Conflict 的成因并使用 padding 解决
- 能用 Tiling 模式优化矩阵乘法 Kernel
- 能根据场景选择正确的内存类型(常量/共享/全局/统一)
- 能使用
cudaMemPrefetchAsync优化统一内存的性能