2.2 Transformer全貌及代码实现
在拆解 Transformer 的各个零部件之前,先站远一点看清整台”机器”的全貌。本文从 2017 年原始论文的 Encoder-Decoder 架构讲起,完整剖析 Encoder、Decoder 的内部结构与数据流,随后追溯架构演化的三条路线(Encoder-only、Encoder-Decoder、Decoder-only),聚焦当前大模型的主流选择——Decoder-only,最后用 PyTorch 从零实现完整的 Encoder-Decoder Transformer,将理论与代码一一对应。
📑 目录
- 1. 为什么需要先看全貌
- 2. 原始 Transformer:Encoder-Decoder 架构
- 3. Encoder 内部结构详解
- 4. Decoder 内部结构详解
- 5. 架构演化:三条分岔路
- 6. Decoder-only:当前大模型的端到端结构
- 7. 从配置文件看真实模型结构
- 8. 三种架构的工程特性对比
- 9. PyTorch 代码实现:从零搭建 Transformer
- 总结
- 自我检验清单
- 参考资料
1. 为什么需要先看全貌
学习 Transformer 最常见的误区是一上来就钻进 Self-Attention 的矩阵乘法细节,结果”只见树木不见森林”——知道 $QK^T$ 怎么算,却说不清整个模型从接收一句话到吐出下一个字经历了哪些步骤。
打个比方:你第一次走进一座陌生的工厂,最有效的方式不是立刻拆开流水线上某台机器的齿轮箱,而是先沿着车间走一圈——看看原材料从哪个口进来,经过几道工序,在哪里变成成品出去。有了这张”工厂地图”,之后再拆任何一台机器时,你都知道它在整条流水线上的位置和职责。
本文就是那张地图。读完之后,你会清楚:
- 原始 Transformer 的 Encoder 和 Decoder 各自负责什么,如何协作
- 三种架构变体(Encoder-only、Encoder-Decoder、Decoder-only)各自砍掉了什么、保留了什么
- 当前大语言模型从 token 输入到概率输出的完整数据流路径
- 每个组件在端到端流程中的角色,为后续深入学习各模块奠定坐标系
2. 原始 Transformer:Encoder-Decoder 架构
2017 年 Vaswani 等人发表的 “Attention Is All You Need” 提出了一种完全基于注意力机制的序列转换模型,彻底抛弃了此前占统治地位的 RNN/LSTM。这就是 Transformer 的起源。
2.1 设计动机:为机器翻译而生
原始 Transformer 要解决的是序列到序列(Seq2Seq) 问题——给定一个输入序列(如英文句子),生成一个输出序列(如法文翻译)。这天然需要两个阶段:先理解输入,再生成输出。于是模型被分成了两个对称的部分:
- Encoder(编码器):把输入序列压缩成一组”理解后的表示”
- Decoder(解码器):基于这组表示,逐步生成输出序列
这就像人类翻译的工作方式:先把英文句子完整读一遍,在脑子里形成理解(编码),然后逐词写出法文译文(解码),写每个词时都会回头参考自己对原文的理解。
2.2 整体架构图
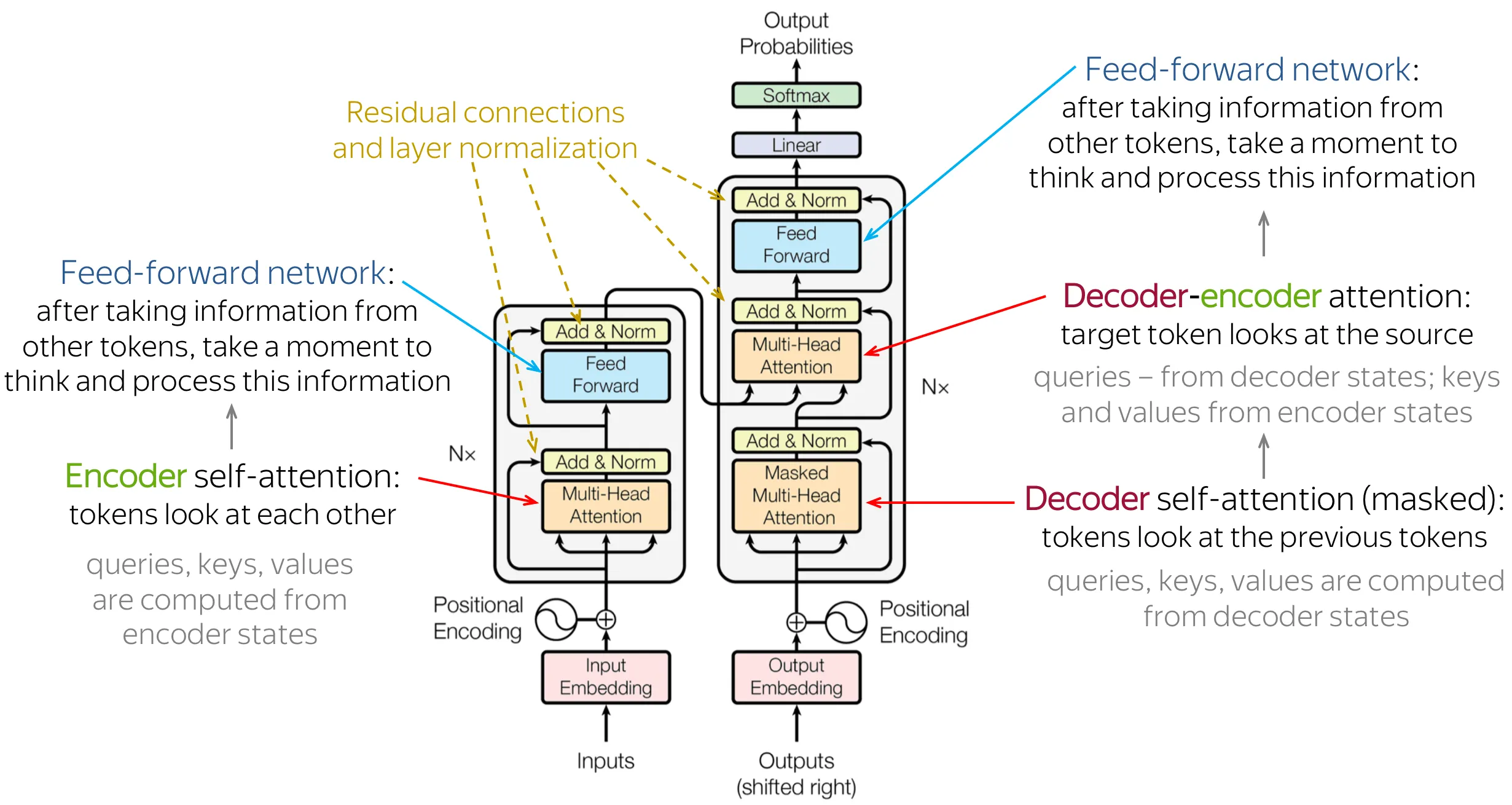
原始论文中,Encoder 和 Decoder 各有 $N = 6$ 层,隐藏维度 $d_{model} = 512$,注意力头数 $h = 8$,FFN 中间维度 $d_{ff} = 2048$。
2.3 三种注意力机制的分工
原始 Transformer 中一共用到了三种不同的注意力机制,它们虽然底层计算方式相同(都是 Scaled Dot-Product Attention),但 Q、K、V 的来源不同,扮演的角色也不同:
| 注意力类型 | 所在位置 | Q 来自 | K、V 来自 | 作用 |
|---|---|---|---|---|
| Encoder Self-Attention | Encoder 层 | 输入序列 | 输入序列 | 输入 token 之间互相交换信息 |
| Masked Decoder Self-Attention | Decoder 层 | 已生成序列 | 已生成序列 | 已生成的 token 之间互相交换信息(不能看未来) |
| Cross-Attention | Decoder 层 | 已生成序列 | Encoder 输出 | 生成过程中”回头查看”输入序列 |
用翻译的比喻来理解:
- Encoder Self-Attention 就像读原文时反复揣摩每个词与其他词的关系
- Masked Decoder Self-Attention 就像写译文时回顾自己已经写了什么
- Cross-Attention 就像写译文时回头对照原文
3. Encoder 内部结构详解
Encoder 的职责是”读懂”输入序列。它接收 token 序列,输出同样长度的上下文表示序列——每个位置的输出向量都融合了整个输入序列的信息。
3.1 输入处理
在进入 Encoder 层之前,原始输入需要经过两步处理:
Token Embedding:将每个 token ID 映射为一个 $d_{model}$ 维的稠密向量。这个映射通过一个可学习的嵌入矩阵 $W_{emb} \in \mathbb{R}^{V \times d_{model}}$ 实现,其中 $V$ 是词表大小。
Positional Encoding:由于 Attention 机制本身不包含位置信息(打乱 token 顺序,计算结果不变),需要显式注入位置信号。原始论文使用正弦/余弦函数生成位置编码,直接加到 token embedding 上:
$$
\text{Input} = \text{TokenEmbed}(x) + \text{PosEncode}(\text{position})
$$
处理后的输入形状为 $(N_{src}, d_{model})$,其中 $N_{src}$ 是源序列长度。
3.2 单个 Encoder 层的数据流
每个 Encoder 层由两个子模块组成,每个子模块外面包裹着残差连接和 LayerNorm:
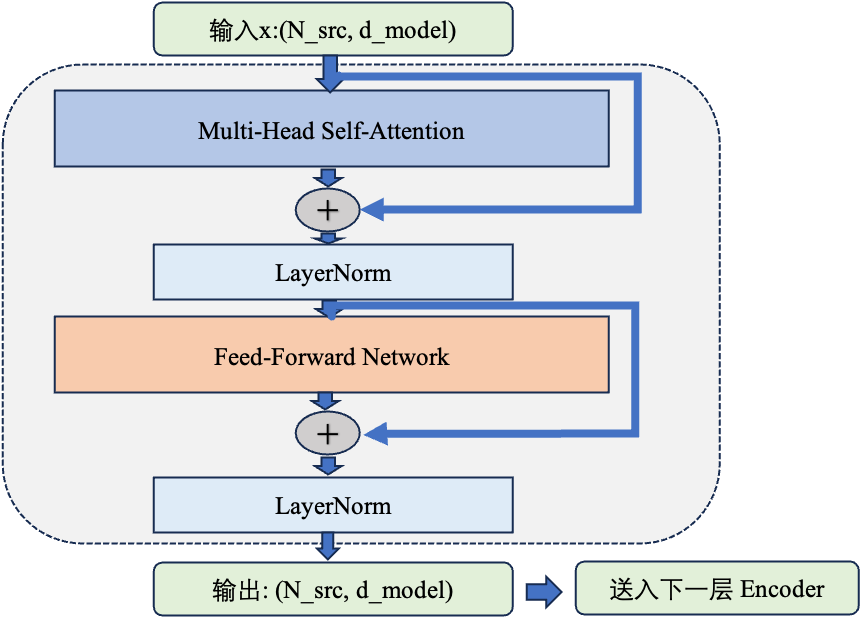
注意原始论文使用的是 Post-Norm(先子层计算,后 LayerNorm),即 $\text{LayerNorm}(x + \text{SubLayer}(x))$。当前大模型普遍切换到了 Pre-Norm(先 LayerNorm,后子层计算),但理解原始设计有助于把握演化脉络。
3.3 Encoder Self-Attention 的关键特性
Encoder 中的 Self-Attention 是双向的(Bidirectional)——每个 token 可以关注序列中所有其他 token,包括它前面和后面的。
用注意力矩阵来表示(1 表示可以关注,形状 $N_{src} \times N_{src}$):
1 | t0 t1 t2 t3 t4 |
完全的全连接——没有任何遮挡。这意味着即使在第一层 Encoder 中,序列末尾的 token 也能直接影响开头的 token 的表示。经过 N 层 Encoder 之后,每个位置的输出向量实际上聚合了整个输入序列的全局信息。
3.4 多层堆叠的信息流动
原始论文使用 6 层 Encoder 堆叠。关键设计是:每层的输入和输出维度完全相同(都是 $(N_{src}, d_{model})$)。这使得各层可以像乐高积木一样自由堆叠——你可以用 6 层、12 层甚至 100 层,只要显存放得下。
直觉上理解多层堆叠的意义:每一层做一次”信息混合与加工”。浅层可能学到词法和句法关系(哪些词是搭配的、哪些词修饰哪些词),深层可能学到更抽象的语义关系(指代消解、隐含关系推理)。层数越多,模型捕捉复杂关系的能力越强,但计算成本也线性增长。
4. Decoder 内部结构详解
Decoder 的职责是”生成”输出序列。它比 Encoder 多一层注意力——Cross-Attention,用来”查阅” Encoder 的输出。
4.1 单个 Decoder 层的数据流
每个 Decoder 层由三个子模块组成(比 Encoder 多一个 Cross-Attention):
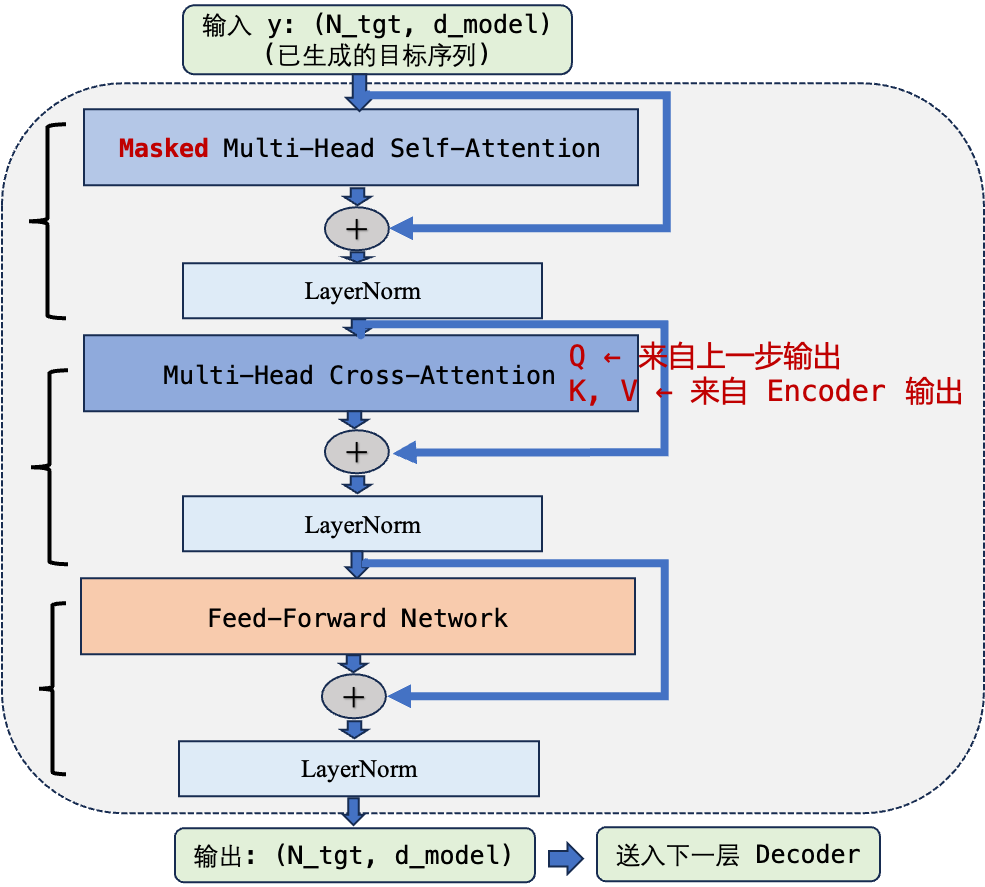
4.2 Masked Self-Attention:不能偷看未来
Decoder 的 Self-Attention 带有因果掩码(Causal Mask),确保在生成第 $i$ 个 token 时只能看到位置 $0$ 到 $i$,不能看到 $i$ 之后的 token。
1 | t0 t1 t2 t3 t4 |
这是一个下三角矩阵。实现上,在 Attention 分数矩阵上加一个上三角的负无穷掩码,softmax 后这些位置的权重就变成零。
为什么需要这个掩码?因为训练时为了效率,我们会把整个目标序列一次性送入 Decoder 并行计算(称为 Teacher Forcing)。如果不加掩码,模型在预测第 3 个词时就能看到第 4、5 个词——等于”开卷考试”,模型学不到任何预测能力。
4.3 Cross-Attention:连接 Encoder 和 Decoder 的桥梁
Cross-Attention 是 Encoder-Decoder 架构中最关键的连接机制。它的计算方式与 Self-Attention 完全相同,唯一的区别是 Q、K、V 的来源不同:
- Q(Query) 来自 Decoder 当前层的输出——“我想要什么信息”
- K(Key)和 V(Value) 来自 Encoder 最后一层的输出——“源序列中有什么信息可供查阅”
$$
\text{CrossAttn}(Q_\text{dec}, K_\text{enc}, V_\text{enc}) = \text{softmax}\left(\frac{Q_\text{dec} K_\text{enc}^\top}{\sqrt{d_k}}\right) V_\text{enc}
$$
形状分析:如果源序列长度为 $N_{src}$,目标序列长度为 $N_{tgt}$,那么:
- $Q_\text{dec} \in \mathbb{R}^{N_{tgt} \times d_{model}}$
- $K_\text{enc}, V_\text{enc} \in \mathbb{R}^{N_{src} \times d_{model}}$
- 注意力分数矩阵:$(N_{tgt} \times N_{src})$——不是方阵!
这里的注意力矩阵不需要因果掩码,因为 Decoder 中的每个 token 应该能够关注 Encoder 输出的所有位置——翻译时你需要看到完整的原文。
4.4 为什么 Decoder 层有三个子模块
把三个子模块串在一起看,每个子模块的职责分工非常清晰:
| 子模块 | 输入 | 作用 | 类比 |
|---|---|---|---|
| Masked Self-Attention | 目标序列自身 | 已生成的词之间互相协调——确保语法通顺、前后一致 | 写作时回顾自己已写的段落 |
| Cross-Attention | 目标序列 + 源序列 | 生成过程中参考源信息——确保翻译忠实于原文 | 写译文时回头对照原文 |
| FFN | 当前 token | 对综合后的信息做深度非线性加工 | 消化理解后形成自己的表达 |
信息流动的顺序很有讲究:先通过 Self-Attention 整合”自己已有的上下文”,再通过 Cross-Attention 补充”来自输入的信息”,最后通过 FFN 做”深度加工”。这种顺序保证了每个 token 在做出预测时,既考虑了已生成的上文,也充分参考了源输入。
5. 架构演化:三条分岔路
原始 Transformer 发布后,研究者们很快发现:Encoder 和 Decoder 并不一定要捆绑在一起。根据任务特性,可以只保留其中一部分。由此演化出三条技术路线。
5.1 Encoder-only:BERT 路线
2018 年,Google 发布 BERT(Bidirectional Encoder Representations from Transformers),只保留了 Transformer 的 Encoder 部分,砍掉了 Decoder 和 Cross-Attention。
核心思想:不做生成任务,专注于”理解”。BERT 通过 Masked Language Model(随机遮住一些 token,让模型预测被遮住的词)来预训练,获得对语言的双向理解能力。
1 | 输入: "The [MASK] sits on the mat" |
保留了什么:双向 Self-Attention + FFN + 残差 + LayerNorm
砍掉了什么:因果掩码、Cross-Attention、自回归生成
适用场景:文本分类、命名实体识别(NER)、句子相似度、信息抽取——所有需要”理解”但不需要”生成”的任务。
5.2 Encoder-Decoder:T5 路线
2019 年,Google 发布 T5(Text-to-Text Transfer Transformer),保留了完整的 Encoder-Decoder 架构,但做了一个重要的范式统一:把所有 NLP 任务都转化为”文本到文本”的格式。
1 | 分类任务: "classify: The movie is great" → "positive" |
T5 证明了一个有趣的观点:只要输入输出格式统一,同一个 Encoder-Decoder 架构可以处理几乎所有 NLP 任务。后续的 BART、mBART、UL2 等模型也沿袭了这条路线。
保留了什么:完整的 Encoder + Decoder + Cross-Attention
改进了什么:统一的 text-to-text 训练格式
5.3 Decoder-only:GPT 路线
2018 年,OpenAI 发布 GPT(Generative Pre-trained Transformer),只保留了 Transformer 的 Decoder 部分(去掉 Cross-Attention),通过纯粹的”预测下一个 token”来训练。
1 | 输入: "The cat sits on" |
保留了什么:因果 Self-Attention + FFN + 残差 + LayerNorm
砍掉了什么:Encoder、Cross-Attention、双向注意力
从 GPT-1 到 GPT-4,从 LLaMA 到 Mistral、Qwen、DeepSeek,Decoder-only 路线最终成为大模型时代的绝对主流。下一节我们深入剖析它的完整结构。
6. Decoder-only:当前大模型的端到端结构
Decoder-only 架构砍掉了 Encoder 和 Cross-Attention,整个模型可以用一个极其简洁的公式描述:输入 token → Embedding → N 层 Decoder Block → 预测下一个 token。
6.1 端到端数据流
以一次实际的 LLM 推理为例,跟踪数据从输入到输出的完整流程:
1 | 用户输入: "什么是注意力机制" |
整个过程的数学表达可以简洁地写成:
$$
P(\text{next_token} \mid x_1, x_2, \ldots, x_n) = \text{Softmax}\left(W_{lm} \cdot \text{RMSNorm}\left(\text{DecoderBlocks}^{(L)}(\text{Embed}(x))\right)\right)
$$
6.2 五大组件拆解
把 Decoder-only 模型从头到尾拆成五个功能模块:
(1)Token Embedding
作用如同一本”单词-向量”对照字典。模型维护一个嵌入矩阵 $W_{emb} \in \mathbb{R}^{V \times d_{model}}$,输入一个 token ID,输出对应行的向量。
- LLaMA-2-7B 的词表大小 $V = 32000$,$d_{model} = 4096$,所以 $W_{emb}$ 有 $32000 \times 4096 \approx 131M$ 参数
- 对比模型总参数 6.7B,Embedding 只占约 2%
(2)Decoder Block 堆叠
这是模型的”主体”,占据了 95%+ 的参数和计算量。每个 Block 内部的结构在入门篇和后续深入文章中详细讲解,这里只强调几个全局性质:
- 维度守恒:每个 Block 的输入和输出形状严格相同,都是 $(N, d_{model})$,这使得 Block 可以任意堆叠
- 参数不共享:每一层的 $W_Q, W_K, W_V, W_O, W_{gate}, W_{up}, W_{down}$ 都是独立的参数,不同层之间不共享权重
- 层数决定深度:LLaMA-2-7B 有 32 层,LLaMA-2-70B 有 80 层,层数越多模型越”深”,理论上能捕捉更复杂的模式
(3)Final LayerNorm
最后一层 Decoder Block 输出后,还有一个单独的归一化层。它的作用是在送入 LM Head 之前稳定数值范围,防止深层网络中数值漂移导致输出分布不稳定。
(4)LM Head(语言模型头)
一个简单的线性层 $W_{lm} \in \mathbb{R}^{d_{model} \times V}$,将 $d_{model}$ 维的隐藏状态映射到词表大小 $V$ 的 logits 向量。
一个重要的工程优化:Weight Tying(权重共享)。许多模型(包括 LLaMA)让 LM Head 的权重直接复用 Token Embedding 的权重矩阵(转置后使用),即 $W_{lm} = W_{emb}^\top$。这不仅减少了 131M 参数,而且从语义上也合理——“把向量映射回 token”和”把 token 映射为向量”应该是互逆操作。
(5)Softmax + 采样
将 logits 转化为概率分布,再根据采样策略(Greedy、Top-k、Top-p、Temperature 等)选出下一个 token。不同的采样策略会显著影响生成质量和多样性——Temperature 越高输出越随机,越低越确定性。
6.3 与原始 Encoder-Decoder 的结构对比
把两种架构并排对比,可以清晰看到 Decoder-only 简化了什么:
| 组件 | Encoder-Decoder | Decoder-only |
|---|---|---|
| Token Embedding | Encoder 和 Decoder 各有一个 | 只有一个 |
| Positional Encoding | 加法注入(Sinusoidal) | 旋转注入(RoPE,在 Attention 时应用) |
| Self-Attention | Encoder: 双向 / Decoder: 因果 | 只有因果掩码的 Self-Attention |
| Cross-Attention | 有(Decoder 每层都有) | 无 |
| FFN | Encoder 和 Decoder 各有 | 每层一个 |
| LayerNorm 位置 | Post-Norm | Pre-Norm(多数大模型) |
| 归一化方式 | LayerNorm | RMSNorm(多数大模型) |
| 输出头 | Linear + Softmax | Linear + Softmax(可能 Weight Tying) |
7. 从配置文件看真实模型结构
理解了架构之后,我们来看几个真实开源模型的配置,把抽象结构与具体数字对应起来。
7.1 LLaMA-2 系列
| 配置项 | 7B | 13B | 70B |
|---|---|---|---|
| $d_{model}$(隐藏维度) | 4096 | 5120 | 8192 |
| $n_{layers}$(层数) | 32 | 40 | 80 |
| $n_{heads}$(注意力头数) | 32 | 40 | 64 |
| $d_k$(每头维度) | 128 | 128 | 128 |
| $d_{ff}$(FFN 中间维度) | 11008 | 13824 | 28672 |
| vocab_size | 32000 | 32000 | 32000 |
| 总参数量 | 6.7B | 13B | 70B |
| 位置编码 | RoPE | RoPE | RoPE |
| 归一化 | RMSNorm | RMSNorm | RMSNorm |
| FFN 激活 | SwiGLU | SwiGLU | SwiGLU |
| KV 头数 | 32 (MHA) | 40 (MHA) | 8 (GQA) |
注意 70B 模型的一个关键区别:它使用 GQA(Grouped-Query Attention),KV 头数只有 8(而非 64),这意味着每 8 个 Q 头共享一组 KV,大幅减少了推理时的 KV Cache 开销。
7.2 从配置反推模型结构
拿到一个模型的配置文件,就能完整还原它的计算图。以 LLaMA-2-7B 为例,逐层展开:
1 | 输入: token_ids (batch, seq_len) |
参数分布:32 层 Decoder Block 占 6,432M / 6,738M $\approx$ 95.5% 的参数。模型的”智慧”几乎全部存储在这些 Block 的权重矩阵中。
7.3 模型规模与层数/宽度的关系
扩大模型有两个维度——加深(增加层数 $L$)和加宽(增加隐藏维度 $d_{model}$)。参数量的粗略公式为:
$$
\text{Params} \approx L \times (12 \cdot d_{model}^2) + V \cdot d_{model}
$$
其中 $12 \cdot d_{model}^2$ 是单层 Decoder Block 的参数量(4 个 Attention 矩阵 + SwiGLU 的 3 个矩阵约等于 $4d^2 + 3 \times \frac{8}{3}d^2 = 12d^2$),$V \cdot d_{model}$ 是 Embedding 的参数量。
从表中可以观察到一个规律:
- 7B → 13B:层数从 32 增到 40(+25%),宽度从 4096 增到 5120(+25%),参数量约翻倍
- 13B → 70B:层数从 40 增到 80(+100%),宽度从 5120 增到 8192(+60%),参数量增长 5.4 倍
参数量对宽度是二次方关系、对深度是线性关系,因此加宽比加深对参数增长的影响更大。
AI Infra 关联:这个二次方关系直接影响显存规划和并行策略。宽度翻倍意味着每层参数量翻四倍,单张卡可能放不下一层——这时需要张量并行(Tensor Parallelism)在层内切分。层数翻倍则可以用流水线并行(Pipeline Parallelism)在层间切分。实际部署中往往需要两者结合。
8. 三种架构的工程特性对比
从 AI Infra 工程师的视角,三种架构在系统设计上有显著差异。
8.1 计算特性对比
| 维度 | Encoder-only | Encoder-Decoder | Decoder-only |
|---|---|---|---|
| 注意力复杂度 | $O(N^2)$,N 为输入长度 | Encoder: $O(N_{src}^2)$ + Cross: $O(N_{tgt} \cdot N_{src})$ + Decoder: $O(N_{tgt}^2)$ | $O(N^2)$,N 为总序列长度 |
| 推理模式 | 单次前向传播(非自回归) | 自回归生成(Decoder 部分) | 自回归生成 |
| KV Cache | 不需要(不做生成) | Encoder KV + Decoder KV 两套 | 一套 Decoder KV |
| 典型推理延迟 | 毫秒级(分类任务) | 较高(两个组件) | 取决于生成长度 |
8.2 并行策略差异
| 并行方式 | Encoder-Decoder | Decoder-only |
|---|---|---|
| 张量并行(TP) | Encoder 和 Decoder 需要各自切分,Cross-Attention 的 KV 来自 Encoder,通信模式更复杂 | 每层结构一致,切分方式统一,通信模式简单 |
| 流水线并行(PP) | 需要决定 Encoder 和 Decoder 各占多少 stage,负载均衡更困难 | 所有层结构相同,均匀切分即可 |
| 序列并行(SP) | 两侧序列长度可能不同,需要分别处理 | 只有一个序列维度,处理统一 |
8.3 为什么 Decoder-only 对工程最友好
除了模型效果之外,Decoder-only 成为大模型主流还有深刻的工程原因:
架构统一性。整个模型只有一种 Block 结构反复堆叠,这意味着:
- CUDA kernel 只需要优化一套(同样的 Attention kernel、同样的 FFN kernel 复用 L 次)
- 并行策略只需要设计一次(不需要 Encoder/Decoder 分别调度)
- 性能分析和瓶颈定位更简单(任意一层的特性代表所有层)
KV Cache 管理简单。只有一套 KV Cache 需要管理,PagedAttention 等优化技术可以直接应用,不需要处理 Encoder 输出的缓存和 Decoder KV Cache 的两套数据。
Scaling 路径清晰。想要更大的模型?增加层数、增加宽度、增加头数——三个旋钮,效果可预测。不需要纠结 Encoder 和 Decoder 的比例分配。
训练数据利用率高。”预测下一个 token” 的训练目标意味着每个 token 都产生一个训练信号(loss),数据利用率接近 100%。而 Encoder-Decoder 的训练信号只在 Decoder 部分产生,Encoder 的梯度全靠 Decoder 的 loss 回传。
9. PyTorch 代码实现:从零搭建 Transformer
理论看完之后,最好的检验方式是亲手写出来。本章用 PyTorch 从零实现完整的 Encoder-Decoder Transformer,每个模块都与前面章节中的结构图一一对应。
依赖导入:
1 | import numpy as np |
9.1 掩码机制:三种 Mask 的实现
掩码是实现中最容易出错的地方。一共有三种,对应第 2 节中描述的三种注意力机制。
Encoder 长度 Mask:同一 batch 中不同样本经过 padding 补齐,需要屏蔽 padding 位置的 Attention 权重。做法是将对应位置的 score 填为 -1e4,过 softmax 后权重趋近于 0。
1 | def get_len_mask(b: int, max_len: int, feat_lens: torch.Tensor, device: torch.device) -> torch.Tensor: |
Decoder Causal Mask(因果掩码):训练时整个目标序列并行输入,但预测位置 $i$ 只能看到位置 $0$ 到 $i$,通过上三角掩码实现。
1 | def get_subsequent_mask(b: int, max_len: int, device: torch.device) -> torch.Tensor: |
torch.triu(..., diagonal=1) 保留严格上三角($j > i$ 的位置),第 $i$ 行只能 attend 到第 $0$ 到 $i$ 列。
Encoder-Decoder Cross-Attention Mask:Decoder 每层的 Cross-Attention 中,K/V 来自 Encoder,需屏蔽 Encoder 输出中 padding 的部分。
1 | def get_enc_dec_mask( |
三种 Mask 的对比:
| Mask 类型 | 使用位置 | 形状 | 目的 |
|---|---|---|---|
| 长度 Mask | Encoder 自注意力 | (b, enc_len, enc_len) | 屏蔽 Encoder padding |
| Causal Mask | Decoder 自注意力 | (b, dec_len, dec_len) | 防止看到未来 token |
| Cross-Attn Mask | Decoder Cross-Attention | (b, dec_len, enc_len) | 屏蔽 Encoder padding |
⚠️ 注意:本文使用 masked_fill_(mask, -1e4),True 表示需要屏蔽。PyTorch 2.0 的 scaled_dot_product_attention 在传入 bool 类型 mask 时语义一致(True 也表示屏蔽);若传入 float 类型 mask,则直接加到 scores 上(用大负数起屏蔽效果)。
9.2 Multi-Head Attention
对应第 3 节中的 Scaled Dot-Product Attention 公式:
$$
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V
$$
实现分四步:线性投影 → 拆分多头 → Scaled Dot-Product Attention → 合并输出。
1 | class MultiHeadAttention(nn.Module): |
💡 提示:原论文标准配置 $d_{model}=512$,$\text{num_heads}=8$,$d_k=d_v=64$,此时 $d_{model} = d_k \times \text{num_heads}$,输入输出维度一致。
9.3 正弦位置编码
对应第 3.1 节中的 Positional Encoding 设计,实现原论文的正弦/余弦公式:
$$
\text{PE}(\text{pos}, 2i) = \sin\left(\frac{\text{pos}}{10000^{2i/d_{model}}}\right), \quad
\text{PE}(\text{pos}, 2i+1) = \cos\left(\frac{\text{pos}}{10000^{2i/d_{model}}}\right)
$$
1 | def pos_sinusoid_embedding(seq_len: int, d_model: int) -> torch.Tensor: |
在 Encoder/Decoder 中通过 nn.Embedding.from_pretrained(..., freeze=True) 将位置编码固定为不可学习参数,使用时直接按位置索引查表。
9.4 Position-wise FFN
对应第 3.2 节中 Encoder 层的 FFN 子模块,本质是对每个 token 独立做两层 MLP:
$$
\text{FFN}(x) = \text{ReLU}(xW_1 + b_1)W_2 + b_2
$$
用 nn.Linear 实现,直接作用于最后一维,无需转置:
1 | class PoswiseFFN(nn.Module): |
9.5 EncoderLayer 与 Encoder
EncoderLayer 对应第 3.2 节的数据流图:Multi-Head Self-Attention + FFN,每个子层外包残差连接和 LayerNorm(Post-Norm 风格)。
1 | class EncoderLayer(nn.Module): |
完整 Encoder:N 个 EncoderLayer 之前先叠加位置编码。
1 | class Encoder(nn.Module): |
9.6 DecoderLayer 与 Decoder
DecoderLayer 对应第 4.1 节的数据流图:三个子层——Masked Self-Attention → Cross-Attention → FFN。
1 | class DecoderLayer(nn.Module): |
完整 Decoder:对目标序列做 Word Embedding,叠加位置编码后逐层解码。
1 | class Decoder(nn.Module): |
9.7 组装完整 Transformer
将 Frontend(输入特征变换)、Encoder、Decoder 和 LM Head 组合为完整模型,对应第 2.2 节的整体架构图:
1 | class Transformer(nn.Module): |
9.8 前向验证
用随机 dummy 数据验证完整模型的前向过程:
1 | if __name__ == "__main__": |
输出 logits 形状为 (batch_size, dec_len, vocab_size),对应每个解码步骤在词表上的概率分布,接上交叉熵损失即可训练。
📝 总结
让我们用一张表回顾本文的核心内容:
| 主题 | 要点 |
|---|---|
| 原始 Transformer | Encoder-Decoder 架构,为 Seq2Seq 任务(翻译)设计 |
| 三种注意力 | Encoder Self-Attention(双向)、Masked Decoder Self-Attention(因果)、Cross-Attention(跨序列) |
| Encoder | 双向注意力 + FFN,输出输入序列的上下文表示 |
| Decoder | 因果 Self-Attention + Cross-Attention + FFN,自回归生成 |
| 三条演化路线 | Encoder-only(BERT)、Encoder-Decoder(T5)、Decoder-only(GPT/LLaMA) |
| Decoder-only 结构 | Embedding → L 层 Decoder Block → Final Norm → LM Head → Softmax |
| Decoder-only 优势 | 统一训练目标、工程简洁、Scaling 清晰、KV Cache 管理简单 |
| 代码实现 | 三种 Mask → MultiHeadAttention → 正弦 PE → FFN → EncoderLayer → DecoderLayer → Transformer |
从全貌视角看,整个 Transformer 的设计哲学可以归纳为三句话:
- Attention 负责信息交互——让 token 之间互相传递信息
- FFN 负责信息加工——对每个 token 独立做非线性变换
- 残差 + 归一化负责训练稳定——确保深层网络能有效训练
这三个支柱加上”堆叠”的思想(把相同的 Block 重复 N 次),就构成了 Transformer 的全部精髓。后续深入学习各模块时,请随时回来翻看这张全貌图,确认你研究的零件在整台机器中的位置。
🎯 自我检验清单
- 能画出原始 Transformer 的 Encoder-Decoder 整体结构图,标注三种注意力的位置和 Q/K/V 来源
- 能解释 Encoder Self-Attention、Masked Decoder Self-Attention、Cross-Attention 各自的作用和区别
- 能说清 Encoder-only、Encoder-Decoder、Decoder-only 三种架构分别保留和砍掉了原始 Transformer 的哪些组件
- 能从头到尾描述 Decoder-only LLM 的完整推理数据流:token ID → Embedding → N 层 Block → Norm → LM Head → Softmax → 采样
- 能默写 Decoder-only 模型的五大组件(Embedding、Block 堆叠、Final Norm、LM Head、Softmax)及各自职责
- 能根据给定的配置参数($d_{model}$、$n_{layers}$、vocab_size 等)估算模型的总参数量
- 能解释 Weight Tying 的含义和工程价值
- 能从工程角度说出至少三个 Decoder-only 对 AI Infra 更友好的原因
- 能说清三种 Mask 的名称、使用场景和 shape(
(b, q_len, k_len)) - 能解释 Causal Mask 为什么用上三角矩阵,以及
torch.triu(..., diagonal=1)的含义 - 能描述 Multi-Head Attention 的四个步骤:线性投影 → 拆分多头 → Scaled Dot-Product Attention → 合并输出
- 能写出正弦位置编码的公式,并解释为什么 Transformer 需要显式位置编码而 RNN 不需要
- 能运行完整的前向验证代码,并解释输出
logits的维度含义
📚 参考资料
- Attention Is All You Need (Vaswani et al., 2017) — Transformer 原始论文,Encoder-Decoder 架构与正弦位置编码的完整描述
- BERT: Pre-training of Deep Bidirectional Transformers (Devlin et al., 2018) — Encoder-only 路线的开创性工作
- Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (Raffel et al., 2019) — T5 论文,Encoder-Decoder 的统一范式
- Language Models are Unsupervised Multitask Learners (Radford et al., 2019) — GPT-2 论文,Decoder-only 路线的奠基
- LLaMA: Open and Efficient Foundation Language Models (Touvron et al., 2023) — LLaMA 模型架构与配置详解
- Sequence to Sequence Learning with Neural Networks (Sutskever et al., 2014) — Encoder-Decoder 框架的奠基论文
- Are Sixteen Heads Really Better than One? (Michel et al., 2019) — 对多头注意力有效性的实验分析
- The Illustrated Transformer (Jay Alammar) — 图文并茂的 Transformer 入门教程
- The Annotated Transformer (Harvard NLP) — 论文逐行对应 PyTorch 实现
- PyTorch nn.MultiheadAttention — PyTorch 官方 Multi-Head Attention 实现文档