2.1 AI Infra工程师为什么必须懂Transformer
Transformer 是当今所有大语言模型的共同骨架,而 AI Infra 工程师的全部工作——从底层算子到分布式训练再到推理服务——都围绕这个骨架展开。本文将系统阐述 AI Infra 的定义与技术栈定位、Transformer 如何成为”通用底座”、以及两者之间的精确映射关系,帮助读者建立”我到底在优化什么”的全局认知。
📑 目录
- 1. 什么是 AI Infra
- 2. Transformer 如何成为通用底座
- 3. AI Infra 各层级与 Transformer 模块的对应关系
- 4. 端到端案例:一次 LLM 推理请求的完整旅程
- 5. 学习建议:如何构建完整的知识体系
- 自我检验清单
- 参考资料
1. 什么是 AI Infra
1.1 一句话定义
AI Infra(AI Infrastructure,人工智能基础设施)可以用一句话概括:用系统工程的方法,把硬件算力高效地”喂”给模型。
打个比方,如果把训练和运行大模型想象成举办一场万人宴席,那么算法研究员是菜单的设计者——他们决定做什么菜、用什么配方;而 AI Infra 工程师则是负责搭建厨房、调度厨师、管理食材供应链的后勤总指挥。菜做得好不好一半看配方,另一半看厨房运转是否顺畅——灶台够不够、传菜快不快、食材会不会在仓库里堆成山。AI Infra 就是这个”后勤体系”。
1.2 AI Infra 在技术栈中的位置
要理解 AI Infra 的职责边界,可以把整个 AI 技术栈画成一个分层架构:
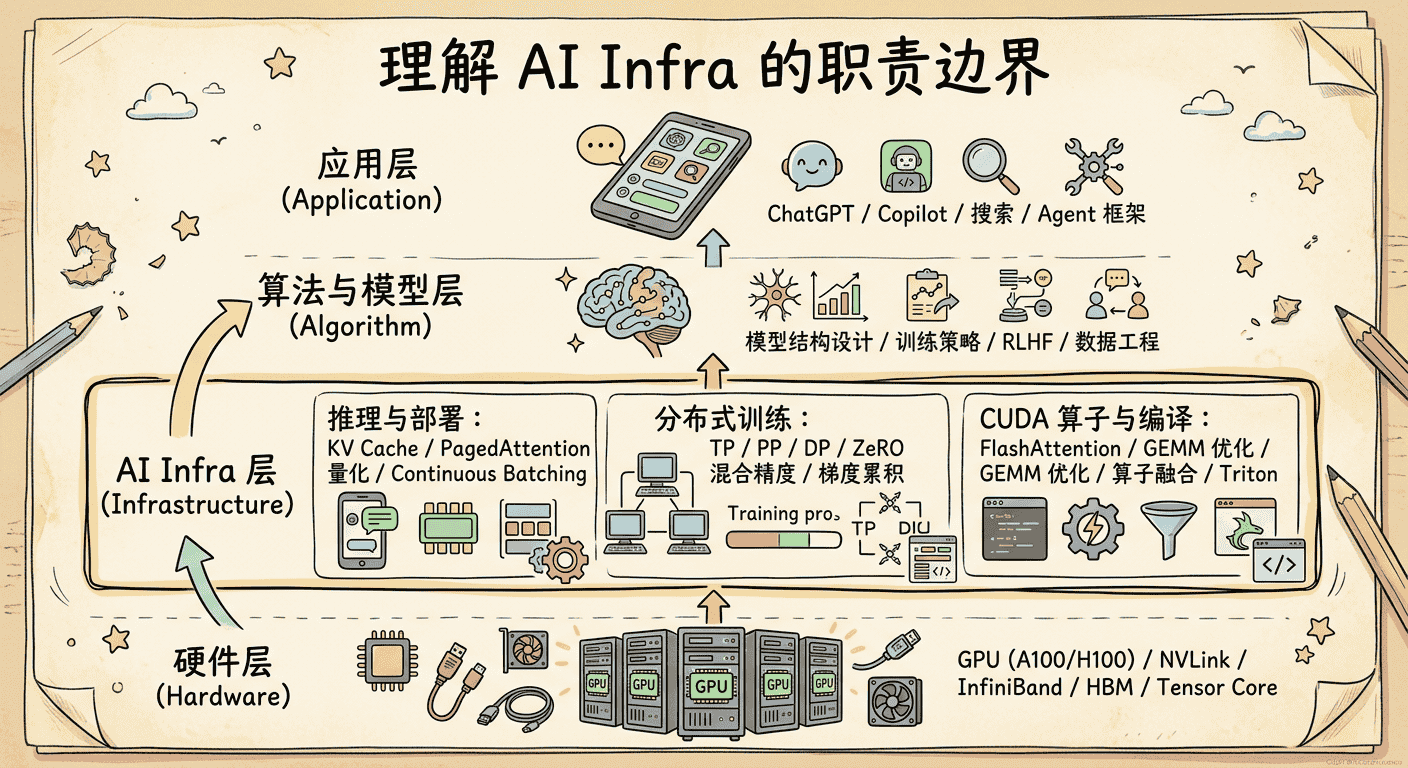
从图中可以看出,AI Infra 正好夹在”算法与模型层”和”硬件层”之间——它的使命是做好上下两层的翻译官:把上层模型的计算需求,翻译成下层硬件能够高效执行的指令。向上,它要理解模型长什么样、每个模块需要多少计算和显存;向下,它要理解 GPU 的存储层次、通信拓扑和并行能力。而这个”上层模型”,在当今几乎就等于 Transformer。
1.3 AI Infra 工程师的日常工作
AI Infra 工程师的具体工作因团队而异,但核心任务可以归纳为以下几类:
🍎 CUDA 算子开发与优化
这一类工作最”底层”,直接和 GPU 硬件打交道。典型任务包括:为 Attention 计算编写高效的 CUDA kernel(如实现或改进 FlashAttention)、优化矩阵乘法(GEMM)以充分利用 Tensor Core、将多个小算子融合为一个大 kernel 减少显存读写。做这些工作的前提是你知道要优化的”对象”是什么——比如 FlashAttention 优化的是 Self-Attention 中 $QK^T$ 和 Softmax 的计算与显存访问模式,如果你不知道 Self-Attention 的计算流程,就无法理解 FlashAttention 在做什么。
🍎 分布式训练
当模型大到一张 GPU 装不下时,就需要把模型”切开”放到多张卡甚至多台机器上协同训练。这涉及张量并行(将矩阵乘法沿某个维度切分到多卡)、流水线并行(将模型的不同层分配到不同卡)、数据并行(每张卡处理不同的数据批次然后同步梯度)等策略。每种策略的”切分点”都直接取决于 Transformer 的结构——张量并行沿着 Attention 的多头维度切,流水线并行沿着 Decoder Block 的堆叠方向切。
🍎 推理部署与优化
训练完成后,如何让模型高效地服务用户请求是另一大类工作。核心挑战包括 KV Cache 的显存管理(每个请求需要缓存 Attention 计算中的 Key 和 Value)、Continuous Batching(动态组批提高 GPU 利用率)、量化(用更低精度表示权重和缓存以节省显存和带宽)、Speculative Decoding(用小模型”猜测”多个 token 再由大模型一次性验证)。这些优化的对象无一例外都是 Transformer 内部的某个具体模块。
🍎 性能分析与系统调优
使用 Nsight Systems、Nsight Compute、torch.profiler 等工具分析训练或推理的性能瓶颈,判断当前是计算受限还是带宽受限,找到最值得优化的热点算子。这同样要求你知道每个 kernel 对应 Transformer 的哪个模块,否则看到一个耗时很长的 kernel 名称,连它在做什么都搞不清楚。
2. Transformer 如何成为通用底座
2.1 Transformer 之前的世界:RNN/LSTM 的困境
在 Transformer 出现之前,处理序列数据(文本、语音、时间序列)的主流架构是 RNN(循环神经网络)及其改进版本 LSTM(长短期记忆网络)。
RNN 的核心思想很直观:按顺序逐个处理序列中的元素,每一步将当前输入和上一步的”记忆”(隐藏状态)结合,产生新的”记忆”传递给下一步。这就像你读一本小说,逐字逐句地读,每读一句就在脑中更新对故事情节的理解。
这个设计有两个致命弱点:
❌ 无法并行训练。由于每一步的计算依赖上一步的输出,整个序列必须串行处理。对于一个包含 2048 个 token 的序列,RNN 需要顺序执行 2048 步,无法利用 GPU 数千个核心的并行能力。这就像一条单车道公路——不管你有多少辆车(GPU 核心),每次只能过一辆。
❌ 长距离依赖的遗忘问题。尽管 LSTM 通过门控机制缓解了原始 RNN 的梯度消失问题,但信息在长距离传递时仍然会衰减。想象你在听一段很长的演讲,演讲开头提到的一个关键定义,到了一小时后的结论部分,你可能已经记不太清了。LSTM 也面临类似的”遗忘”挑战,在处理数千 token 以上的长序列时效果明显下降。
这两个弱点共同构成了一个瓶颈:模型既不能高效训练,也不能有效利用长上下文信息。这正是 Transformer 要解决的问题。
2.2 Attention Is All You Need:范式转换
2017 年,Vaswani 等人在论文”Attention Is All You Need”中提出了 Transformer 架构。这篇论文的核心贡献是用 Self-Attention 机制完全取代了循环结构,从根本上解决了上述两个问题。
Self-Attention 的做法是:让序列中的每个 token 直接和所有其他 token 进行”交互”——计算两两之间的”注意力权重”,然后根据权重聚合信息。这意味着第 1 个 token 和第 2000 个 token 之间的信息传递不需要经过中间 1999 步,而是一步到位。用前面的比方说,这就像从逐字逐句读小说变成了同时看到整页内容并自由跳转关注重点段落。
这带来了两个根本性的优势:
⭕ 天然的并行性。所有 token 对之间的注意力权重可以同时计算——本质上就是一次矩阵乘法 $QK^T$。矩阵乘法是 GPU 最擅长的操作,数千个 CUDA Core 和 Tensor Core 可以同时参与计算。这让训练速度相比 RNN 有了质的飞跃。
⭕ 全局信息访问。每个 token 可以直接”看到”序列中所有其他 token 的信息,不存在长距离传递的衰减。注意力机制让模型自主学习该关注哪些位置,而不是被迫按照固定的顺序传递信息。
当然,这种”全员互联”的设计也有代价——计算复杂度为 $O(N^2)$,其中 $N$ 是序列长度。但在实际的训练场景中,并行带来的加速远远超过了 $O(N^2)$ 带来的额外计算量,尤其是在 GPU 的强大矩阵运算能力支撑下。而 $O(N^2)$ 带来的显存和计算问题,恰恰成为了 AI Infra 优化的核心战场(FlashAttention、KV Cache 管理等)。
2.3 从原始 Transformer 到 LLM 家族
原始的 Transformer 采用 Encoder-Decoder 结构,主要用于机器翻译。此后,研究者们在其基础上发展出了多个方向:
✳️ BERT(2018):只使用 Encoder 部分,通过双向注意力(每个 token 能看到前后所有 token)和掩码语言模型预训练,在自然语言理解任务上取得突破。BERT 验证了”大规模预训练 + 下游微调”这一范式的有效性。
✳️ GPT 系列(2018-2023):只使用 Decoder 部分,通过单向注意力(每个 token 只能看到前面的 token)和自回归预训练,在文本生成任务上不断突破。GPT-2 展示了大规模语言模型的文本生成能力,GPT-3 证明了 scaling law(更多参数 + 更多数据 = 更好的效果),GPT-4 则展示了大模型在多模态理解和复杂推理任务上的显著能力提升。
✳️ LLaMA(2023):Meta 开源的 Decoder-only 大模型,在架构上采用了 Pre-Norm(RMSNorm)、SwiGLU 激活函数、RoPE 旋转位置编码等当前最佳实践。LLaMA 的开源让整个社区能够在统一的架构基础上进行研究和优化,极大地推动了 AI Infra 工具链的发展——vLLM、SGLang、Megatron-LM 等框架的默认支持对象首先就是 LLaMA 架构。
✳️ 后续演进(Mistral、Qwen、DeepSeek 等):这些模型在 LLaMA 的基础上引入了 GQA(Grouped-Query Attention)、MoE(混合专家模型)、MLA(Multi-head Latent Attention)等架构变种,但它们的核心骨架始终是 Transformer Decoder。
纵观这段历史,一个关键事实浮现:无论模型的名字如何变化、规模如何增长、应用场景如何拓展,底层的计算单元始终是 Transformer 的那几个核心模块——Self-Attention、FFN、LayerNorm、位置编码。这就是 AI Infra 工程师必须懂 Transformer 的根本原因:你优化的对象几年来几乎没有变过,变的只是规模和细节。
3. AI Infra 各层级与 Transformer 模块的对应关系
理解了 AI Infra 的工作范围和 Transformer 的历史地位之后,现在来看最核心的问题:AI Infra 每一层的优化工作,具体对应 Transformer 的哪个模块?
下表给出了完整的映射关系,每一行代表一项具体的 AI Infra 优化技术与它作用的 Transformer 模块。
| AI Infra 层级 | 优化技术 | 对应的 Transformer 模块 |
|---|---|---|
| CUDA 算子优化 | FlashAttention / 高效 GEMM | Self-Attention($QK^T$ 和 $PV$ 矩阵乘法) |
| CUDA 算子优化 | Fused Softmax / Online Softmax | Self-Attention(Softmax 归一化) |
| CUDA 算子优化 | LayerNorm kernel 融合 | 每个 Decoder Block 的归一化层 |
| CUDA 算子优化 | RoPE 融合到 Attention kernel | 位置编码(旋转 Q 和 K 向量) |
| 分布式训练 | 张量并行(TP) | Attention 的多头切分 + FFN 的矩阵切分 |
| 分布式训练 | 流水线并行(PP) | Decoder Block 的层级堆叠结构 |
| 分布式训练 | ZeRO 显存优化 | 所有参数矩阵的存储与梯度同步 |
| 分布式训练 | 混合精度(BF16/FP8) | 所有权重矩阵与激活值的数据类型 |
| 推理部署 | KV Cache 管理 | Self-Attention(K 和 V 缓存) |
| 推理部署 | PagedAttention | KV Cache 的显存分页与碎片管理 |
| 推理部署 | 量化(INT4/INT8/FP8) | 所有权重矩阵和 KV Cache |
| 推理部署 | Speculative Decoding | 自回归生成的串行瓶颈 |
下面逐一解读为什么存在这些对应关系。
3.1 CUDA 算子优化层
1️⃣ FlashAttention 与 Self-Attention 的 $QK^T$ / $PV$ 计算
Self-Attention 需要计算一个 $N \times N$ 的注意力矩阵($N$ 为序列长度),标准实现会把这个完整的矩阵写入 GPU 的高带宽显存(HBM),显存占用为 $O(N^2)$。当序列长度从 2K 增长到 128K 时,显存需求增长 4096 倍。FlashAttention 的核心贡献是将这个巨大的矩阵分块(tiling),每个小块在 GPU 的片上缓存(SRAM)中完成 $QK^T$、Softmax、$PV$ 的全部计算,避免将完整的 $N \times N$ 矩阵写入 HBM。这项优化直接作用于 Self-Attention 的两次核心矩阵乘法,因此要理解 FlashAttention 就必须先理解 Attention 的计算流程。
2️⃣ Fused Softmax 与 Attention 的归一化步骤
Softmax 操作需要对注意力分数矩阵的每一行先求最大值、再求指数和、最后归一化——标准实现需要三遍扫描(第一遍求 max,第二遍求 exp 之和,第三遍归一化)。Online Softmax 算法将前两遍合并,只需两遍扫描即可完成,这个优化被集成到 FlashAttention 中,并结合 tiling 技术进一步实现了分块意义上的单次 pass。Softmax 是 Attention 计算管线中的一个关键步骤,把它与前后的矩阵乘法融合在一起可以大幅减少中间结果的显存读写。
3️⃣ LayerNorm kernel 融合
每个 Transformer Decoder Block 包含两个 LayerNorm 操作(Pre-Norm 架构下分别在 Attention 和 FFN 之前)。LayerNorm 本身计算量不大,但需要对整个特征向量做两遍扫描(算均值/方差和归一化),是典型的 Memory Bound 操作。CUDA 优化中通常将 Residual Add + LayerNorm 融合为一个 kernel,减少一次完整的 HBM 读写——理解这个融合的前提是知道残差连接和 LayerNorm 在 Transformer Block 中的具体位置。
4️⃣ RoPE 融合到 Attention kernel
旋转位置编码(RoPE)的计算本质是对 Q 和 K 向量的每对相邻维度做旋转变换,计算量不大但调用频繁。将它融合到 Attention kernel 中可以避免为这个小操作单独启动一个 GPU kernel 的开销。这项优化的前提是理解 RoPE 在 Attention 计算流程中的位置——它作用于 Q 和 K 的线性投影之后、$QK^T$ 矩阵乘法之前。
3.2 分布式训练层
1️⃣ 张量并行(TP)与 Attention 多头 / FFN 矩阵
张量并行的核心思想是将一个大矩阵乘法切分到多张 GPU 上并行计算。Transformer 中有两个天然的切分点。第一个是 Multi-Head Attention:比如 32 个 Attention 头可以均匀分配到 4 张 GPU 上,每张卡处理 8 个头,这种切分不需要卡间通信直到最后一步的输出投影。第二个是 FFN:Megatron-LM 将 FFN 的升维矩阵 $W_{up}$ 按列切分、降维矩阵 $W_{down}$ 按行切分,使得中间的激活值不需要跨卡通信。这两种切分策略都直接依赖于你对 Attention 多头结构和 FFN 升维-降维结构的理解。
2️⃣ 流水线并行(PP)与 Decoder Block 堆叠
一个大模型通常由几十层 Decoder Block 堆叠而成(如 LLaMA-2-7B 有 32 层)。流水线并行将这些层分成若干段,分配到不同的 GPU 上——比如前 8 层在 GPU 0,第 9-16 层在 GPU 1,以此类推。数据像流水线一样依次流过每段。这种策略之所以可行,根本原因在于每个 Decoder Block 的输入输出维度完全相同(都是 $(N, d_{model})$),前一个 Block 的输出可以直接作为下一个 Block 的输入,天然支持分段。
3️⃣ ZeRO 显存优化与所有参数矩阵
ZeRO 的策略是将训练过程中的”重复存储”消除——标准数据并行中,每张 GPU 都保存完整的模型参数、梯度和优化器状态,而 ZeRO 将这些按切片分摊到各卡上。这项优化作用于模型的所有参数矩阵——包括 Attention 的 $W_Q / W_K / W_V / W_O$ 和 FFN 的 $W_{gate} / W_{up} / W_{down}$。理解模型的参数量分布(FFN 约占 2/3,Attention 约占 1/3)对于评估 ZeRO 的显存节省效果和通信开销至关重要。
3.3 推理部署层
1️⃣ KV Cache 与 Self-Attention 的 K/V 矩阵
LLM 的自回归生成每一步只输出一个 token,但 Attention 计算需要用新 token 的 Query 去和所有历史 token 的 Key 做内积。如果不缓存,每一步都要重新计算所有历史 token 的 K 和 V——纯粹的浪费。KV Cache 将每层、每步的 K 和 V 存储在显存中复用。这项优化直接作用于 Self-Attention 模块中 K 和 V 的生命周期管理。
2️⃣ PagedAttention 与 KV Cache 的显存碎片
不同请求的序列长度不同,KV Cache 的大小也不一样。传统的预分配方式会造成大量的显存碎片——短请求分配了过多空间浪费,长请求可能因为找不到足够的连续空间而被拒绝。PagedAttention 借鉴操作系统的虚拟内存分页机制,将 KV Cache 切成固定大小的”页”按需分配,彻底解决碎片问题。这个优化的根源在于 KV Cache 的动态增长特性——每生成一个新 token,KV Cache 就增加一”行”。
3️⃣ 量化与所有权重矩阵 / KV Cache
量化的本质是用更少的比特位表示数值——比如从 FP16(16 位)压缩到 INT4(4 位),权重占用的显存直接降为 1/4。这项技术作用于 Transformer 中所有的权重矩阵($W_Q, W_K, W_V, W_O, W_{gate}, W_{up}, W_{down}$)以及 KV Cache。理解每个矩阵的数值分布特征(比如 FFN 的某些层是否有异常大的 activation outlier)对于选择合适的量化策略至关重要。
4️⃣ Speculative Decoding 与自回归生成的串行瓶颈
自回归生成的根本瓶颈在于每次只能生成一个 token,GPU 的大量算力被浪费。Speculative Decoding 的思路是用一个小而快的 Draft 模型先”猜”出多个 token,再由大模型一次性验证——猜对的直接用,猜错的重新采样。这项优化直接针对 Transformer Decoder 自回归生成的串行特性,本质上是用并行验证来加速串行生成。
4. 端到端案例:一次 LLM 推理请求的完整旅程
为了将上面的理论映射到实践,让我们追踪一个具体的推理请求,从用户发出提问到收到回答,看数据如何流经 Transformer 的每个模块,以及每个环节对应哪些 AI Infra 优化。
假设我们部署了一个 LLaMA-2-7B 模型(32 层 Decoder Block,$hiddendim = 4096$,32 个 Attention 头),使用 vLLM 推理引擎,用户发送了请求:”请用一句话解释什么是 Transformer”。
4.1 Tokenize 与 Embedding
1 | 用户输入 → Tokenizer → Token IDs: [3529, 671, 19, 13563, ...](约 10 个 token) |
AI Infra 关联:Tokenizer 在 CPU 上执行。如果并发量极大,CPU 端的 tokenize 开销可能成为瓶颈,需要用 Nsight Systems 检查是否存在 GPU idle gap。
4.2 Prefill 阶段:并行处理整个 Prompt
所有 10 个 input token 同时进入模型,经过 32 层 Decoder Block。在每一层中:
LayerNorm:对输入做归一化。
1 | (10, 4096) → RMSNorm → (10, 4096) |
AI Infra 优化:Residual Add + RMSNorm 融合为一个 CUDA kernel,减少一次 HBM 读写。
QKV 线性投影:生成 Q、K、V 矩阵。
1 | Q = X * W_Q: (10, 4096) x (4096, 4096) = (10, 4096) → reshape (10, 32, 128) |
AI Infra 优化:三次 GEMM 操作是张量并行(TP)的切分点之一——如果使用 4 卡 TP,每张卡只计算 8 个头对应的 QKV。
RoPE 位置编码:对 Q 和 K 做旋转。
1 | Q, K → 按位置旋转 → Q', K' (形状不变) |
AI Infra 优化:RoPE 计算量小但调用频繁,通常融合到后续的 Attention kernel 中。
Self-Attention 计算:
1 | S = Q' * K'^T / sqrt(128): (10, 128) x (128, 10) = (10, 10) [每个头独立] |
AI Infra 优化:FlashAttention 将 $QK^T$、Scale、Mask、Softmax、$PV$ 全部融合在一个 kernel 中,利用 tiling 技术在 SRAM 中完成计算。Prefill 阶段的 batch 维度较大(10 个 token),属于 Compute Bound 操作。
缓存 K 和 V:将本层的 K 和 V 存入 KV Cache。
AI Infra 优化:vLLM 的 PagedAttention 以”页”为单位分配 KV Cache 存储空间。这 10 个 token 的 KV 被写入预分配的物理页中。
残差连接 + LayerNorm + FFN:
1 | 残差加法: h = input + attention_output (10, 4096) |
AI Infra 优化:FFN 的三个大矩阵($W_{gate}$, $W_{up}$, $W_{down}$)是模型参数的大头(约占 2/3)。在 TP 中,$W_{gate}$ 和 $W_{up}$ 按列切分、$W_{down}$ 按行切分。在量化场景中,这三个矩阵是 INT4/INT8 量化的主要对象。
经过全部 32 层后:最终输出 + Final LayerNorm + LM Head → 词表概率分布 → 采样得到第一个输出 token。
至此,Prefill 阶段完成。用户从发出请求到看到第一个字的时间就是 TTFT(Time To First Token)。
4.3 Decode 阶段:逐 Token 生成
从第二个输出 token 开始,进入 Decode 阶段。每一步只有 1 个新 token 参与计算:
1 | 每一步: |
与 Prefill 阶段的关键区别:
- 矩阵乘法退化为矩阵-向量乘(batch 维度只有 1),GPU 算力远远用不满
- 大部分时间花在从 HBM 搬运 KV Cache 数据,属于 Memory Bound 操作
- 每步完成后 KV Cache 增长一行
这一阶段对应的 AI Infra 优化最为密集:
| 环节 | 瓶颈 | 对应优化技术 |
|---|---|---|
| 逐 token 串行 | GPU 利用率低 | Speculative Decoding(猜测+验证) |
| KV Cache 搬运 | HBM 带宽受限 | FlashDecoding(分块并行化 Decode Attention) |
| KV Cache 增长 | 显存消耗线性增长 | PagedAttention(分页管理) |
| KV Cache 大小 | 长序列/高并发下显存不够 | KV Cache 量化(INT4/INT8/FP8) |
| 并发请求混合 | 短请求被长请求拖累 | Continuous Batching(动态组批) |
| Prefill 与 Decode 互扰 | 尾延迟失控 | Prefill/Decode 解耦部署 |
4.4 全链路示意
下面将整次请求的完整数据流与 AI Infra 优化的对应关系汇总为一张图:
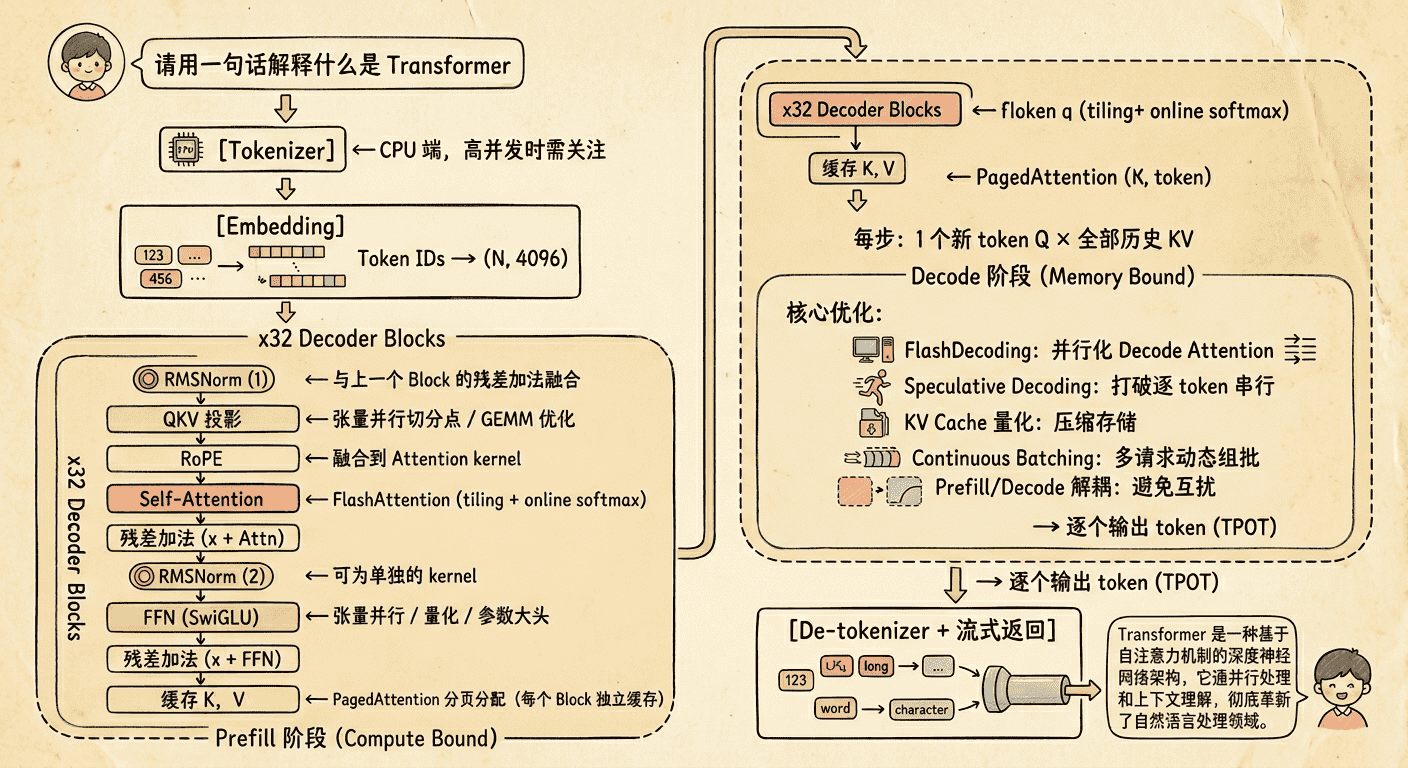
从这个端到端案例中可以清楚看到:推理请求经过的每一个环节——从 Embedding 到 Attention 到 FFN 到自回归生成——都是某项 AI Infra 优化技术的”着力点”。如果你不理解 Transformer 的内部结构,就无法定位性能瓶颈出在哪个模块,也无法评估优化方案的效果。
5. 学习建议:如何构建完整的知识体系
理解了”为什么必须懂 Transformer”之后,下一步是如何高效地学习。以下是建议的学习路径,结合本系列文章的结构来构建完整的知识体系。
5.1 先”见树”再”见林”
不建议一上来就去读 FlashAttention 或 Megatron-LM 的论文——那样你会发现到处都是你不认识的符号和概念。正确的顺序是:
第一步:搞懂 Transformer 的每个模块。参阅本系列的《Transformer架构-快速入门》一文,确保你能在白板上画出完整的 Decoder Block 结构、标注每一步的维度、默写 Attention 公式。这是所有后续学习的根基。
第二步:建立”模块-优化”的映射关系。也就是本文第三节的内容。每当你接触一项新的优化技术时,先问自己:”它优化的是 Transformer 的哪个模块?那个模块的计算瓶颈是什么?”
第三步:分层深入。根据你的实际工作方向,选择 CUDA 算子优化、分布式训练、推理部署中的一个或多个方向深入学习。每个方向的深入都会反过来加深你对 Transformer 架构的理解。
5.2 持续关注架构演进
Transformer 的核心骨架虽然稳定,但细节在持续演进:GQA 改变了 KV 头的数量、MoE 改变了 FFN 的激活方式、MLA 改变了 KV Cache 的压缩方式。每一项架构变种都会影响 AI Infra 的优化策略。建议关注主流模型(LLaMA、DeepSeek、Qwen、Mistral)的技术报告,留意它们在架构上的改动,并思考这些改动对训练和推理系统的影响。
🎯 自我检验清单
完成本文学习后,检验自己是否真正理解了 AI Infra 与 Transformer 的关系:
- 能用自己的语言解释什么是 AI Infra,它在 AI 技术栈中处于什么位置,上下游分别是什么
- 能说清 RNN/LSTM 的两个核心弱点(串行、遗忘),以及 Transformer 如何用 Self-Attention 解决它们
- 能列出至少 3 项 CUDA 算子优化技术及其对应的 Transformer 模块,并解释对应关系
- 能列出至少 3 项分布式训练技术及其对应的 Transformer 模块,并解释对应关系
- 能列出至少 3 项推理优化技术及其对应的 Transformer 模块,并解释对应关系
- 给定一个 LLM 推理请求,能追踪数据流经 Transformer 各模块的过程,并指出每个环节对应哪些 AI Infra 优化
- 能回答”为什么 AI Infra 工程师必须懂 Transformer”这个问题,给出至少两个具体理由(而不是空泛的”因为很重要”)
📚 参考资料
论文
- Attention Is All You Need (Vaswani et al., 2017):https://arxiv.org/abs/1706.03762 – Transformer 原始论文
- BERT: Pre-training of Deep Bidirectional Transformers (Devlin et al., 2018):https://arxiv.org/abs/1810.04805 – Encoder-only 预训练范式
- Language Models are Unsupervised Multitask Learners (Radford et al., 2019, GPT-2):https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf – GPT-2 技术报告
- Language Models are Few-Shot Learners (Brown et al., 2020, GPT-3):https://arxiv.org/abs/2005.14165 – 大规模语言模型的 Scaling Law 验证
- LLaMA: Open and Efficient Foundation Language Models (Touvron et al., 2023):https://arxiv.org/abs/2302.13971 – 开源大模型的里程碑
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness (Dao et al., 2022):https://arxiv.org/abs/2205.14135 – Memory-aware Attention 优化
- Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism (Shoeybi et al., 2019):https://arxiv.org/abs/1909.08053 – 张量并行与流水线并行
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models (Rajbhandari et al., 2019):https://arxiv.org/abs/1910.02054 – 显存优化
- Efficient Memory Management for Large Language Model Serving with PagedAttention (Kwon et al., 2023):https://arxiv.org/abs/2309.06180 – vLLM / PagedAttention
教程与博客
- The Illustrated Transformer (Jay Alammar):https://jalammar.github.io/illustrated-transformer/ – 图文并茂的 Transformer 入门
- Andrej Karpathy: Let’s build GPT from scratch:https://www.youtube.com/watch?v=kCc8FmEb1nY – 从零手写 GPT
- 3Blue1Brown: But what is a GPT: https://www.youtube.com/watch?v=wjZofJX0v4M – 直觉级理解 Transformer
- The Annotated Transformer (Harvard NLP):https://nlp.seas.harvard.edu/annotated-transformer/ – 论文逐行对应 PyTorch 实现