2.0 Transformer架构-快速入门篇
Transformer 是大模型时代的”通用底座”——CUDA 层优化它的算子,分布式层切分它的参数,推理层加速它的生成。本文从 AI Infra 工程师的视角出发,带你理解这个”后续所有优化的对象”到底长什么样,为什么长这样,以及每个模块将在后续的哪些优化中被反复提及。
📑 目录
- 1. 为什么 AI Infra 工程师必须懂 Transformer
- 2. Transformer 网络结构全貌
- 3. Self-Attention 机制
- 4. 前馈网络(FFN)
- 5. 位置编码
- 6. LayerNorm 与残差连接
- 7. 完整的 Transformer Decoder Block
- 8. 从 Transformer 到 LLM:自回归生成
- 总结
- 自我检验清单
- 参考资料
1. 为什么 AI Infra 工程师必须懂 Transformer
如果你准备深入 AI Infra——无论是写 CUDA kernel、搞分布式训练还是做推理部署——你面对的核心工作对象都是同一个东西:Transformer 模型。
这就像汽车工程师必须懂发动机结构一样。你不需要自己设计发动机(那是算法研究员的活),但你必须知道曲轴在哪、活塞怎么运动、油路怎么走——否则你怎么知道该优化哪个零件?
具体来说,AI Infra 各个层级的工作都直接对应 Transformer 的某个模块:
| AI Infra 层级 | 核心工作 | 对应的 Transformer 模块 |
|---|---|---|
| CUDA 算子优化 | FlashAttention、高效 GEMM kernel | Self-Attention 中的 $QK^T$/PV 矩阵乘法 |
| CUDA 算子优化 | Fused Softmax、Online Softmax | Attention 中的 softmax 计算 |
| CUDA 算子优化 | LayerNorm kernel 融合 | 每个 Block 中的归一化层 |
| 分布式训练 | 张量并行(Tensor Parallelism) | Attention 的多头切分、FFN 的矩阵切分 |
| 分布式训练 | 流水线并行(Pipeline Parallelism) | 模型的多层 Decoder Block 堆叠结构 |
| 分布式训练 | ZeRO 显存优化 | 所有参数矩阵的存储与通信 |
| 推理部署 | KV Cache 管理 | Self-Attention 中的 K、V 矩阵 |
| 推理部署 | PagedAttention | KV Cache 的显存碎片问题 |
| 推理部署 | 量化(INT4/INT8/FP8) | 所有权重矩阵和 KV Cache |
一句话总结:不懂 Transformer,就不知道自己在优化什么。 后续学习中遇到的每一个优化技术,都能在本文中找到它所作用的具体模块。
2. Transformer 网络结构全貌
在逐个拆解各模块之前,先从宏观视角看一眼 Transformer 的整体结构——就像拆装一台发动机之前,先看一眼总装图,知道有哪些零部件、它们如何连接。
2.1 原始 Transformer:Encoder-Decoder 架构
2017 年 “Attention Is All You Need” 论文提出的原始 Transformer 由两大部分组成:
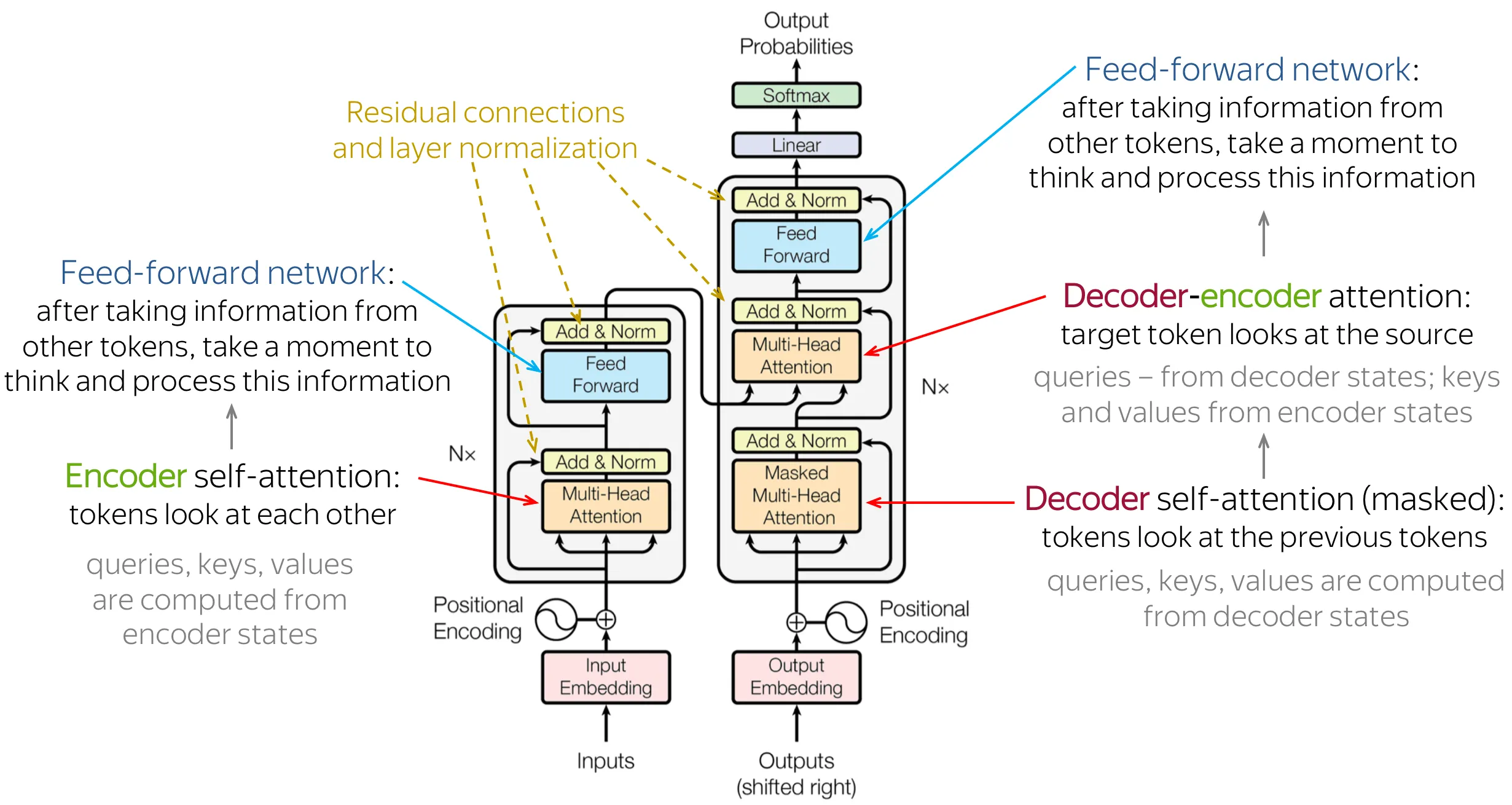
- Encoder:读取输入序列,生成上下文表示。每层包含一个 Self-Attention 和一个 FFN,所有 token 可以互相关注(双向注意力)
- Decoder:基于 Encoder 的输出,自回归地生成目标序列。每层包含一个带因果掩码的 Self-Attention(只能看到已生成的 token)、一个 Cross-Attention(关注 Encoder 输出)和一个 FFN
这种 Encoder-Decoder 结构最初是为机器翻译设计的——Encoder 理解源语言,Decoder 生成目标语言。
2.2 当前大模型的主流:Decoder-only 架构
GPT 系列的成功证明了一个关键洞察:只用 Decoder 就够了。当前几乎所有主流大语言模型——GPT、LLaMA、Mistral、Qwen、DeepSeek——都采用 Decoder-only 架构,砍掉了 Encoder 和 Cross-Attention,只保留带因果掩码的 Self-Attention。
整体结构可以概括为三段式——输入层、N 层 Decoder Block 堆叠、输出层:
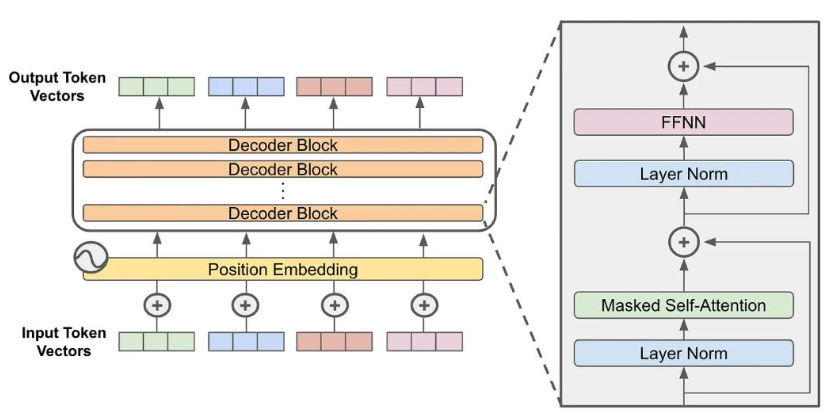
整个模型的核心就是中间那 N 层 Decoder Block 的反复堆叠。每个 Block 的结构完全相同,包含两个子模块:
- Masked Self-Attention:让每个 token 从前面的 token 中聚合信息(第 3 节详解)
- FFN:对每个 token 的信息做独立的非线性变换(第 4 节详解)
每个子模块前有 LayerNorm 归一化(第 6 节详解),后有残差连接把子模块输入直接加回来(第 6 节详解)。位置信息通过 RoPE 在 Attention 计算时注入(第 5 节详解)。
这里你可能会有个疑问:为啥这个 Decoder-only 架构中的 Decoder块 和 Encoder-Decoder 架构中的Decoder块不一样,这就是后面将会讲的 Pre-Norm vs Post-Norm 区别。
2.3 三种架构变体的对比
| 架构 | 代表模型 | 注意力方式 | 典型应用 |
|---|---|---|---|
| Encoder-only | BERT、RoBERTa | 双向注意力(每个 token 看所有 token) | 文本分类、NER、信息抽取 |
| Encoder-Decoder | T5、BART、原始 Transformer | Encoder 双向 + Decoder 因果 + Cross-Attention | 翻译、摘要、Seq2Seq 任务 |
| Decoder-only | GPT、LLaMA、Mistral、Qwen | 因果注意力(每个 token 只看前面的 token) | 文本生成、对话、代码生成 |
Decoder-only 之所以成为大模型的主流选择,核心原因有两个:
- 统一的训练目标:所有任务都可以转化为”预测下一个 token”,不需要针对不同任务设计不同的架构
- 工程简洁性:只有一种 Block 结构,推理时的 KV Cache 管理、并行策略都更简单直接
本文后续所有内容都围绕 Decoder-only 架构展开——这正是 AI Infra 工程师日常打交道最多的结构。
3. Self-Attention 机制
Self-Attention 是 Transformer 的核心,也是计算量和显存消耗最密集的模块。几乎所有 AI Infra 的重量级优化——FlashAttention、KV Cache、张量并行——都围绕它展开。
3.1 直觉理解:Attention 在做什么
先从一个真实的语言难题出发:
句子 A:*The bank of the river.(河边)
句子 B:Money in the bank.*(银行)
同一个词 “bank” 在两句话里含义截然不同。机器翻译时如何判断?答案是看上下文中的其他词:句子 A 里 “river”(河流)权重最高,句子 B 里 “money”(钱)权重最高。这种”让每个词去关注其他词、用相关程度加权汇总语义”的机制,就是 Self-Attention。
用大白话说:Attention 就是让句子中的每个词去”关注”其他所有词,然后根据关注程度加权汇总信息,从而得到一个融合了上下文的”新含义”。
更进一步,打个检索的比方:你在查一本百科全书里关于”苹果”的信息,你会先生成一个查询(Query):”苹果是什么?”,然后翻阅每一页的标题(Key)来判断相关性,最后把相关页面的正文内容(Value)按相关程度加权合并。Attention 做的正是这件事:
- Query(Q):我想查什么——当前词想要获取的信息
- Key(K):索引/标题——每个词用来被别人匹配的标识
- Value(V):实际内容——匹配成功后要传递的信息
在 Self-Attention 中,序列里的每个 token 都同时扮演这三种角色:它既是提问者(生成 Q),也是被查询的索引(生成 K),还是信息的提供者(生成 V)。通过 Q 和 K 的匹配来计算”注意力权重”,再用这些权重对 V 做加权求和,就完成了信息的聚合。
💡 提示:”银行”还是”河岸”的歧义问题,RNN 时代需要把前面所有词的信息按顺序一步步传递过来才能解决;Self-Attention 则让所有词在同一步内直接互相”比对”,长距离依赖不再衰减。
3.2 计算过程:从输入到输出的完整流程
假设我们有一个长度为 $N$ 的序列,每个 token 用一个 $d$ 维向量表示,输入矩阵 $X$ 的形状为 $(N, d)$。
第一步:线性投影生成 Q、K、V
输入 X 分别乘以三个权重矩阵,得到 Query、Key、Value:
$$
Q = X W_Q, \quad K = X W_K, \quad V = X W_V
$$
其中 $X \in \mathbb{R}^{N \times d}$,$W_Q, W_K, W_V \in \mathbb{R}^{d \times d}$,输出均为 $(N, d)$。
其中 $W_Q$、$W_K$、$W_V$ 是可学习的参数矩阵,形状都是 $(d, d)$。这三次矩阵乘法就是三次 GEMM 操作——后续 CUDA 优化和张量并行的核心对象之一。
第二步:计算注意力分数
用 Q 和 K 的内积来衡量每对 token 之间的”匹配度”:
$$
S = QK^\top \in \mathbb{R}^{N \times N}
$$
得到的 $S$ 是一个 $N \times N$ 的矩阵,$S[i][j]$ 表示第 $i$ 个 token 对第 $j$ 个 token 的关注程度(原始分数)。
第三步:缩放(Scale)
将分数除以 $\sqrt{d_k}$($d_k$ 是每个头的维度,后面会解释):
$$
S_{\text{scaled}} = \frac{S}{\sqrt{d_k}}
$$
为什么要缩放?直觉上说,当维度 $d_k$ 很大时,Q 和 K 的内积值会变得很大(因为是 $d_k$ 个分量相加),导致 softmax 的输入值差异悬殊。softmax 对大数值非常敏感——输入差距一大,输出就会”极化”成接近 one-hot 的分布,梯度几乎为零,训练就卡住了。除以 $\sqrt{d_k}$ 能把方差拉回到 1 附近,让 softmax 工作在一个梯度比较健康的区间。
第四步:Softmax 归一化
对每一行做 softmax,把原始分数变成概率分布(每行之和为 1):
$$
A = \text{softmax}(S_{\text{scaled}}) \in \mathbb{R}^{N \times N}
$$
$A[i][j]$ 现在表示:第 $i$ 个 token 分配给第 $j$ 个 token 的注意力权重,每行之和为 1。
AI Infra 关联:Softmax 是一个看似简单但在高性能场景下需要精心优化的算子。标准实现需要对每行做两遍扫描(第一遍求最大值和指数和,第二遍归一化),Online Softmax 算法将其合并为一遍扫描,FlashAttention 正是基于此实现了 Attention 的高效融合。
第五步:加权求和
用注意力权重 A 对 Value 矩阵 V 做加权求和:
$$
\text{Output} = AV \in \mathbb{R}^{N \times d}
$$
最终每个 token 得到一个 $d$ 维向量,其中融合了它”应该关注”的所有其他 token 的信息。
完整公式(一行总结)
$$
\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V
$$
第六步:输出投影
最后还要过一个输出投影矩阵 $W_O$:
$$
\text{Final} = \text{Output} \cdot W_O \in \mathbb{R}^{N \times d}
$$
$W_O$ 将多头拼接后的结果映射回模型的隐藏维度(下一节详述)。
3.3 为什么复杂度是 $O(N^2)$
从上面的计算过程可以直接看出瓶颈所在。
关键一步是 $QK^T$,形状为 $(N, d) \times (d, N)$,结果是一个 $(N, N)$ 矩阵。这一步的:
- 计算量:$O(N^2 \cdot d)$——$N^2$ 个元素,每个元素需要 $d$ 次乘加
- 显存占用:$O(N^2)$——需要存储完整的 $N \times N$ 注意力矩阵
类似地,$A \cdot V$ 的形状是 $(N, N) \times (N, d)$,计算量也是 $O(N^2 \cdot d)$。
所以 Self-Attention 的总复杂度是 $O(N^2 \cdot d)$,通常简写为 $O(N^2)$(因为 $d$ 是模型的固定常数)。
这意味着什么?当序列长度 $N$ 从 2K 增加到 128K 时,计算量和注意力矩阵的显存占用增长了 $(128K/2K)^2 =$ 4096 倍。这就是为什么长上下文支持如此困难。
AI Infra 关联:这个 $O(N^2)$ 的显存瓶颈直接催生了 FlashAttention。标准实现需要把完整的 $N \times N$ 注意力矩阵写入 HBM(GPU 的高带宽显存),而 FlashAttention 通过 tiling(分块计算)+ online softmax,让注意力矩阵始终驻留在片上 SRAM 中,将 HBM 访问量从 $O(N^2)$ 降到 $O(N)$。计算量没变,但显存访问量大幅减少——这正是”Memory-aware”优化的核心思想。
3.4 Multi-Head Attention:为什么要多头
上面描述的是单头 Attention。实际的 Transformer 使用 Multi-Head Attention(MHA):把 Q、K、V 沿特征维度切分成多个”头”,每个头独立做 Attention,最后把结果拼接起来。
白话解释:一个头只能关注一种”关系模式”(比如语法依赖),多个头就能同时关注多种关系(语法、语义、位置关系等),就像多个人从不同角度看同一个问题,最后综合意见。
具体来说,假设模型隐藏维度 $d_{model} = 4096$,头数 $h = 32$,则每个头的维度 $d_k = d_{model} / h = 128$。
以 $d_h = 128$,$h = 32$ 为例:
$$
Q = X \cdot W_Q \quad (N, 4096) \times (4096, 4096) = (N, 4096)
$$
$$
Q_{\text{heads}} = Q.\text{reshape}(N, 32, 128) \quad \text{切分为 32 个头}
$$
同理切分 K 和 V。每个头独立计算 Attention:
$$
\text{head}_i: (N, 128) \times (128, N) \to (N, N) \xrightarrow{\text{softmax}} (N, N) \times (N, 128) \to (N, 128)
$$
最后把 32 个头的输出拼接并投影:
$$
\text{Output} = \text{Concat}(\text{head}_1, \text{head}_2, \ldots, \text{head}_{32})
$$
$$
\text{Final} = \text{Output} \cdot W_O
$$
多头机制的参数组成:
- $W_Q$:$(4096, 4096)$,即 $4096 \times 4096 = 16M$ 参数
- $W_K$:$(4096, 4096)$,$16M$ 参数
- $W_V$:$(4096, 4096)$,$16M$ 参数
- $W_O$:$(4096, 4096)$,$16M$ 参数
- 合计:$4 \cdot d_{model}^2 = 64M$ 参数
AI Infra 关联:多头结构天然适合张量并行(Tensor Parallelism)。32 个头可以均匀分配到多张 GPU 上——比如 4 张卡各处理 8 个头,每张卡只需要 1/4 的 QKV 权重和计算量。这就是 Megatron-LM 张量并行的核心思想:沿着”头”的维度切分 Attention 模块。切分之后只需要一次 AllReduce 通信就能将各卡的部分结果汇总。
此外,Attention 头数的变种——MQA(Multi-Query Attention) 让所有头共享一组 KV、GQA(Grouped-Query Attention) 让若干头共享一组 KV——直接影响 KV Cache 的大小和张量并行的切分方式,是推理优化中的核心概念。
4. 前馈网络(FFN)
Attention 负责”信息交互”——让 token 之间互相传递信息。但仅靠信息交互还不够,模型还需要对每个 token 的信息做”深度加工”。这就是前馈网络(Feed-Forward Network,FFN)的工作。
打个比方:Attention 像一场圆桌会议,大家互相交换意见;FFN 则是会后每个人回到自己工位上,独立消化吸收这些信息并形成自己的判断。FFN 对每个 token 独立地做非线性变换,不涉及 token 之间的交互。
4.1 结构:两层线性变换 + 激活函数
标准 FFN 的结构非常简洁——先”升维”再”降维”,中间夹一个非线性激活函数:
$$
\text{FFN}(x) = W_2 \cdot \text{activation}(W_1 x + b_1) + b_2
$$
其中:
- $W_1$:$(d_{model}, d_{ff})$,将维度从 $d_{model}$ 扩展到 $d_{ff}$(通常 $d_{ff} = 4 \cdot d_{model}$)
- 激活函数:引入非线性
- $W_2$:$(d_{ff}, d_{model})$,将维度从 $d_{ff}$ 压缩回 $d_{model}$
以 $d_{model} = 4096$ 为例:
$$x : (N,\ 4096)$$
$$W_1 \cdot x : (N, 4096) \times (4096, 11008) = (N, 11008) \quad \text{升维}$$
$$\text{activate} : (N,\ 11008) \quad \text{非线性变换}$$
$$W_2 \cdot h : (N, 11008) \times (11008, 4096) = (N, 4096) \quad \text{降维}$$
注意:实际的 LLaMA 等模型使用 SwiGLU 激活函数(下面会讲),中间维度是 $(2/3) \times 4 \times d_{model} = 11008$ 而非简单的 $4 \times d_{model}$,这是为了在引入门控机制后保持总参数量基本不变。
4.2 参数量分析:为什么 FFN 是模型参数的大头
让我们算一笔账。对于一个 Transformer Block:
| 模块 | 参数矩阵 | 参数量 |
|---|---|---|
| Attention | $W_Q, W_K, W_V, W_O$ | $4 d_{model}^2$ |
| FFN(标准) | $W_1, W_2$ | $2 d_{model} \cdot d_{ff} = 8 d_{model}^2$ |
| FFN(SwiGLU) | $W_{gate}, W_{up}, W_{down}$ | $3 d_{model} \cdot (8/3 \cdot d_{model}) = 8 d_{model}^2$ |
粗略地看,FFN 的参数量大约是 Attention 的 2 倍。在整个 Transformer Block 中,FFN 贡献了约 2/3 的参数。
这个比例有重要的工程含义:
AI Infra 关联:由于 FFN 的参数量占大头,在做张量并行时,FFN 的切分方式直接影响通信开销。Megatron-LM 将 $W_1$ 按列切分、$W_2$ 按行切分,使得中间结果不需要 AllReduce,只在最后做一次 AllReduce——这种切分方式正是利用了 FFN 的”先升维后降维”结构。在混合专家模型(MoE)中,FFN 进一步被拆分为多个”专家”,引入了 Expert Parallelism 这一新的并行维度。
4.3 激活函数activation演进:ReLU → GELU → SwiGLU
激活函数看似是一个小细节,但它的选择直接影响模型的训练稳定性和最终效果。
ReLU(Rectified Linear Unit)
$$
\text{ReLU}(x) = \max(0, x)
$$
最经典的激活函数,简单高效。问题在于:当输入为负时输出恒为 0,对应的神经元”永久死亡”,丢失了信息。
GELU(Gaussian Error Linear Unit)
$$
\text{GELU}(x) = x \cdot \Phi(x)
$$
其中 $\Phi(x)$ 是标准正态分布的累积分布函数(CDF)。
直觉上说,GELU 不是像 ReLU 那样粗暴地”开/关”,而是根据输入值的大小给一个平滑的”通过概率”——值越大越可能通过,值越小越可能被抑制,但不会完全归零。GPT 系列和 BERT 都使用 GELU。
SwiGLU(Swish-Gated Linear Unit)
$$
\text{FFN}_\text{SwiGLU}(x) = W_\text{down} \cdot \bigl(\text{Swish}(W_\text{gate}, x) \odot (W_\text{up}, x)\bigr)
$$
其中 $\text{Swish}(x) = x \cdot \sigma(x)$,$\sigma$ 为 sigmoid 函数,$\odot$ 表示逐元素乘法。
SwiGLU 是目前大模型的主流选择(LLaMA、Mistral 等均采用)。它引入了一个门控机制:用一个独立的”门”矩阵 $W_{gate}$ 来控制信息的通过量,而不是简单地对所有维度施加相同的激活函数。代价是多了一个 $W_{gate}$ 矩阵(因此 FFN 从两个矩阵变成三个:$W_{gate}$、$W_{up}$、$W_{down}$),但实验表明效果更好。
AI Infra 关联:SwiGLU 的三矩阵结构($W_{gate}$、$W_{up}$、$W_{down}$)与标准 FFN 的两矩阵结构不同,在做 CUDA kernel 融合和张量并行切分时需要单独处理。比如 $W_{gate}$ 和 $W_{up}$ 可以合并为一次 GEMM 来提升 GPU 利用率。
5. 位置编码
5.1 为什么 Transformer 需要位置信息
这是一个容易被忽视但极其重要的问题。
回顾 Self-Attention 的计算过程:$QK^T$ 计算的是每对 token 之间的匹配分数,然后用这些分数对 V 做加权求和。注意——这个过程完全不关心 token 的顺序。
你可以做一个思想实验:把句子”猫追狗”中的三个 token 打乱成”狗猫追”,只要 Q、K、V 的值不变,Attention 的计算结果完全一样。用数学术语说,Attention 操作对输入序列是排列等变的(permutation equivariant)——你怎么打乱输入顺序,输出就跟着同样打乱,但每个 token 聚合到的信息不会变。
但语言显然是有顺序的!”猫追狗”和”狗追猫”意思完全不同。所以我们必须想办法把位置信息注入到 Transformer 中。
5.2 Sinusoidal 位置编码:原始论文方案
“Attention Is All You Need” 论文提出了一种优雅的方案:用不同频率的正弦/余弦函数为每个位置生成一个独特的编码向量,直接加到 token 的 embedding 上。
$$
\text{PE}(\text{pos}, 2i) = \sin\left(\frac{\text{pos}}{10000^{2i/d}}\right)
$$
$$
\text{PE}(\text{pos}, 2i+1) = \cos\left(\frac{\text{pos}}{10000^{2i/d}}\right)
$$
其中 $\text{pos}$ 是 token 在序列中的位置($0, 1, 2, \ldots$),$i$ 是维度索引。
直觉上理解:每个维度对应一个不同”频率”的时钟。低频维度变化缓慢(用来区分远距离位置),高频维度变化快速(用来区分近距离位置)。这就像用”年-月-日-时-分-秒”来编码时间——“年”变化最慢但能区分大时间跨度,”秒”变化最快但只能区分小时间跨度。所有维度组合起来,每个位置就有了唯一的”时间戳”。
优点:
- 不引入可学习参数,编码长度理论上可以任意扩展
- 相对位置信息可以通过线性变换得到(sin/cos 的加法公式)
局限:
- 位置信息是”加”在 embedding 上的,在深层网络中可能被逐渐稀释
- 难以有效外推到训练时未见过的长度
5.3 RoPE(旋转位置编码):当前大模型的主流选择
RoPE(Rotary Position Embedding,旋转位置编码)是目前几乎所有主流大模型(LLaMA、Mistral、Qwen、DeepSeek 等)采用的位置编码方案。
核心思想:不在 embedding 层注入位置信息,而是在计算 Attention 时,通过旋转 Q 和 K 向量来编码位置。
具体做法是把 Q 和 K 向量的每两个相邻维度看作二维平面上的坐标,然后根据 token 的位置按特定角度旋转这个二维向量:
$$
q_{2i}^{\prime} = q_{2i} \cos(\text{pos} \cdot \theta_i) - q_{2i+1} \sin(\text{pos} \cdot \theta_i)
$$
$$
q_{2i+1}^{\prime} = q_{2i} \sin(\text{pos} \cdot \theta_i) + q_{2i+1} \cos(\text{pos} \cdot \theta_i)
$$
其中 $\theta_i = \dfrac{1}{10000^{2i/d}}$ 是与 Sinusoidal 类似的频率参数,K 向量做同样的旋转。
这样做的关键性质是:旋转后的 Q 和 K 做内积时,结果只依赖于两个 token 的相对位置差,而不是绝对位置。数学上可以证明:
$$
\langle \text{RoPE}(q, m); \text{RoPE}(k, n) \rangle = f(q, k, m - n)
$$
这意味着 Attention 天然编码了相对位置信息,非常符合语言理解的需求(”第 3 个词和第 5 个词之间的关系”比”第 3 个词和第 5 个词各自的绝对位置”更重要)。
为什么 RoPE 成为主流:
- 相对位置编码,天然支持变长输入
- 不引入额外参数
- 与线性 Attention 等变种兼容
- 外推性优于 Sinusoidal(配合 NTK-aware 等插值方法可以扩展上下文长度)
AI Infra 关联:RoPE 的旋转操作(本质是逐元素乘加)计算量不大但调用频繁,通常会被融合到 Attention kernel 中一并完成,避免单独 launch 一个 kernel 的开销。在长上下文场景中,RoPE 的频率参数调整(如 NTK-aware Scaling、YaRN 等)直接影响模型能支持的最大序列长度,这与 KV Cache 管理和显存规划密切相关。
6. LayerNorm 与残差连接
6.1 残差连接:让梯度畅通无阻
残差连接(Residual Connection)的思想来自 ResNet,结构极其简单:
$$
\text{output} = x + \text{SubLayer}(x)
$$
其中 SubLayer 可以是 Attention 层或 FFN 层。
直观理解:在原始信息基础上,只学习增量
可以把残差连接理解为:输出 = 原始信息 + 学到的改动。举个直观例子:
假设 $x$ = “猫在桌子上”,Attention 学到的是 $F(x)$ = “强调’猫’和’桌子’的关系”,那么:
$$
y = x + F(x)
$$
相当于:保留原句,同时增强语义关系。
为什么要这样设计?
1️⃣ 解决深层网络训练困难
Transformer 通常有几十层(LLaMA-2 有 32 层,GPT-4 据传有上百层)。如果没有残差连接,信号传播路径为 $x \to F_1 \to F_2 \to F_3 \to \cdots$,梯度在反向传播时需要经过层层链式乘法,很容易衰减到接近零(梯度消失),深层网络就无法有效训练。
有残差连接后,传播路径变为 $x \to F \to +x \to F \to +x \to \cdots$,梯度可以直接”走捷径”:
$$
\frac{\partial y}{\partial x} = 1 + \frac{\partial F}{\partial x}
$$
由于恒等项 $1$ 的存在,梯度不会变成 $0$,训练更稳定。残差连接提供了一条”高速公路”——梯度可以直接沿残差路径流回浅层,不受中间层变换的影响。
2️⃣ 让模型更容易学习恒等映射
理想情况下,如果某一层不需要做任何变换,只要学到 $F(x) = 0$,输出就等于输入 $y = x$。这意味着网络可以自动”跳过”不需要的层,而不必费力学习一个恒等变换。
3️⃣ 信息不丢失
没有残差连接时,每一层都会”覆盖”原始信息;有残差连接后,原始信息始终被保留并逐层传递。这对 NLP 任务尤其关键——token 的语义信息在层层变换中不能丢失。
6.2 LayerNorm:稳定训练的归一化操作
LayerNorm(Layer Normalization)对每个 token 的特征向量做归一化——减去均值、除以标准差,再通过可学习的缩放参数 $\gamma$ 和偏移参数 $\beta$ 恢复表达能力:
$$
\text{LayerNorm}(x) = \gamma \cdot \frac{x - \mu}{\sqrt{\sigma^2 + \epsilon}} + \beta
$$
其中 $\mu = \text{mean}(x)$,$\sigma^2 = \text{var}(x)$ 沿特征维度($d_\text{model}$)计算,$\epsilon$ 是防止除以零的小常数(如 $10^{-5}$)。
直觉上说,LayerNorm 就像一个”信号调节器”——无论输入信号的绝对大小如何波动,都把它拉回到一个标准范围内,防止某些维度的值过大或过小影响后续计算。
6.3 Pre-Norm vs Post-Norm
LayerNorm 放在子层的前面还是后面,是一个看似微小但影响深远的设计选择。
Post-Norm(原始论文方案)
$$
\text{output} = \text{LayerNorm}(x + \text{SubLayer}(x))
$$
先做子层计算和残差加法,再做归一化。
Pre-Norm(当前大模型的主流选择)
$$
\text{output} = x + \text{SubLayer}(\text{LayerNorm}(x))
$$
先做归一化,再做子层计算,最后做残差加法。
两者的关键区别在于残差路径是否经过 LayerNorm:
- Post-Norm 中,残差路径上有 LayerNorm,梯度回传时会被 LayerNorm 的导数”调制”
- Pre-Norm 中,残差路径是一条”干净”的直通通道,梯度可以无损地回传
为什么大模型普遍用 Pre-Norm:
| 维度 | Post-Norm | Pre-Norm |
|---|---|---|
| 训练稳定性 | 深层模型容易梯度爆炸,需要精心的学习率 warmup | 梯度流更稳定,对超参数不敏感 |
| 最终效果 | 理论上略好(如果能训稳的话) | 略低但差距不大 |
| 工程友好度 | 需要更多调参经验 | “开箱即用”,适合大规模训练 |
实际工程中,当模型规模达到数十亿参数以上时,训练稳定性远比理论上 0.x% 的效果差异重要——训练一次的成本可能是数百万美元,任何导致 loss spike 或 diverge 的风险都不可接受。这就是 Pre-Norm 成为默认选择的原因。
AI Infra 关联:LayerNorm 虽然计算量不大,但它是一个”读写密集”的操作——需要对整个特征向量做两遍扫描(第一遍算均值和方差,第二遍归一化),频繁访问 HBM。在 CUDA 优化中,LayerNorm 通常会与前后的算子融合(比如 Residual Add + LayerNorm 融合为一个 kernel),减少 HBM 读写次数。此外,一些大模型使用 RMSNorm(去掉了减均值的步骤,只做方差归一化)来进一步简化计算。
7. 详解 Transformer Decoder Block
前面我们分别拆解了 Self-Attention、FFN、位置编码、LayerNorm 和残差连接。现在让我们把它们组装起来,看看一个完整的 Transformer Decoder Block 长什么样(图可看前文)。
7.1 数据流图解
以当前大模型主流的 Pre-Norm Decoder-only 架构为例,数据在一个 Block 内的流转如下:
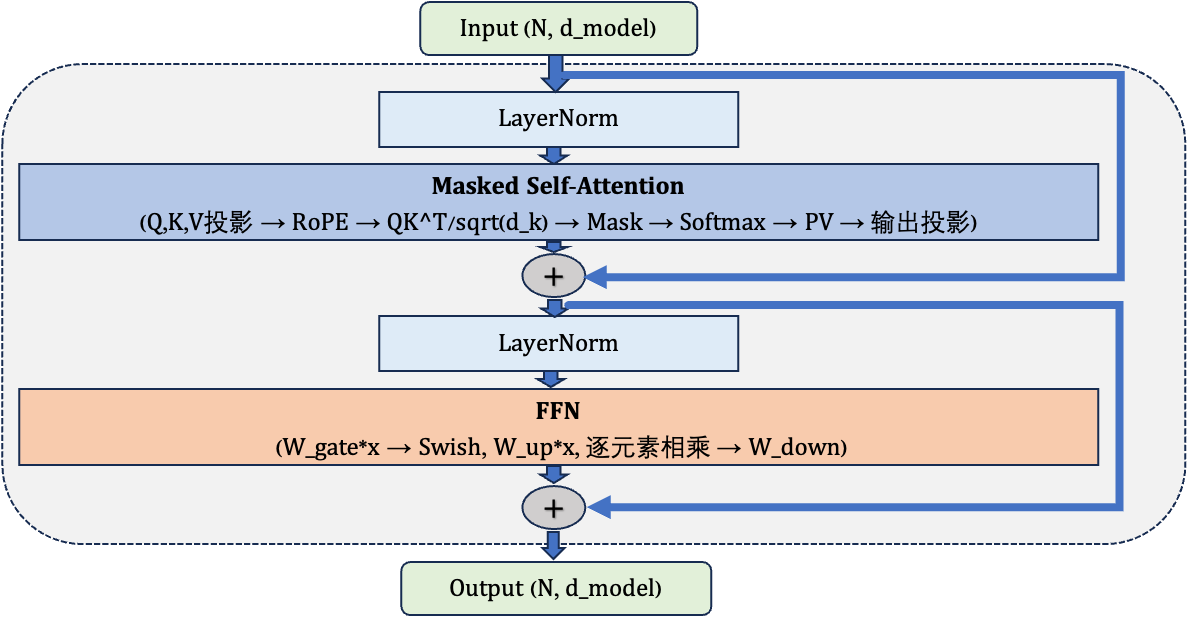
注意这里的 Masked Self-Attention:在 Decoder 架构中,每个 token 只能看到自己和前面的 token,不能”偷看”后面的内容。这是通过在 Attention 分数矩阵上加一个上三角掩码(mask)实现的——把未来位置的分数设为负无穷,softmax 后这些位置的权重就变成 0。
7.2 维度跟踪
让我们用 LLaMA-2-7B 的配置来具体跟踪每一步的张量维度:
- hidden_dim ($d_{model}$) = 4096
- num_heads ($h$) = 32
- head_dim ($d_k$) = 4096 / 32 = 128
- ffn_intermediate_dim = 11008(SwiGLU 的中间维度)
- 序列长度 $N$ = 2048(举例)
- batch_size $B$ = 1(简化讨论,省略 batch 维度)
1 | Input: (2048, 4096) |
从头到尾,数据的形状始终保持 $(N, d_{model})$。这个性质非常重要——它意味着多个 Block 可以像积木一样堆叠,前一个 Block 的输出直接作为下一个 Block 的输入,维度完全兼容。
7.3 参数量手算:LLaMA-2-7B 的参数都花在了哪里
给定配置:
- $d_{model} = 4096$
- num_heads = 32, head_dim = 128
- ffn_intermediate_dim = 11008
- num_layers = 32
- vocab_size = 32000
单个 Decoder Block 的参数量:
| 模块 | 参数矩阵 | 参数量 |
|---|---|---|
| Attention | $W_Q$ $(4096 \times 4096)$ | 16,777,216 |
| Attention | $W_K$ $(4096 \times 4096)$ | 16,777,216 |
| Attention | $W_V$ $(4096 \times 4096)$ | 16,777,216 |
| Attention | $W_O$ $(4096 \times 4096)$ | 16,777,216 |
| FFN | $W_{gate}$ $(4096 \times 11008)$ | 45,088,768 |
| FFN | $W_{up}$ $(4096 \times 11008)$ | 45,088,768 |
| FFN | $W_{down}$ $(11008 \times 4096)$ | 45,088,768 |
| LayerNorm x 2 | $\gamma, \beta$ 各 4096 | 16,384 |
| 单 Block 合计 | ~201M |
整个模型的参数量:
| 组件 | 计算方式 | 参数量 |
|---|---|---|
| Token Embedding | vocab_size $\times$ $d_{model}$ = $32000 \times 4096$ | ~131M |
| 32 层 Decoder Block | $32 \times 201M$ | ~6,432M |
| 最终 LayerNorm | $2 \times 4096$ | ~8K |
| 输出头(LM Head) | $d_{model} \times$ vocab_size = $4096 \times 32000$ | ~131M |
| 总计 | ~6,738M ≈ 6.7B |
注意:LLaMA-2 的 Token Embedding 和 LM Head 通常共享权重(weight tying),如果共享则减去一个 131M,约 6.6B。官方标注的 “7B” 是取整后的近似值。
从参数分布可以看出:
- FFN 占了约 67%(每层 135M / 201M)
- Attention 占了约 33%(每层 67M / 201M)
- Embedding 占比很小(131M / 6738M ≈ 2%)
AI Infra 关联:这个参数量的手算能力是显存规划的基础。6.7B 参数 x 2 Bytes/param(FP16)= ~13.4 GB 的模型权重。加上 Adam 优化器状态(FP32 参数副本 + 一阶动量 + 二阶动量 = 4x 参数量 = ~26.8 GB),以及梯度(~13.4 GB),训练一个 7B 模型的静态显存需求约为 ~54 GB——这就是为什么单张 80GB A100 看似宽裕,实际上加上 Activation 存储后往往需要 ZeRO 优化才能训练。
8. 从 Transformer 到 LLM:自回归生成
到目前为止,我们理解了 Transformer 的内部结构。但一个训练好的模型如何实际地生成文本?这一节讲的是 Transformer 在推理时的工作方式——这与推理优化直接相关。
8.1 自回归生成:一次只输出一个 token
大语言模型(LLM)的文本生成是自回归的——每一步根据前面所有已有的 token,预测下一个最可能的 token。
1 | 用户输入: "人工智能的" |
每一步的”预测”,其实就是把当前所有 token 送入 Transformer 做一次完整的前向传播,最后一层的输出经过 LM Head(一个 $(d_{model}, \text{vocab_size})$ 的线性层)映射到词表大小的向量,再经过 softmax 得到每个 token 的概率分布,从中采样得到下一个 token。
这种逐 token 生成的方式有一个严重的效率问题:每生成一个新 token,都需要对所有历史 token 重新计算 Attention 中的 K 和 V。如果序列长度为 $N$,生成 $N$ 个 token 的总计算量是 $O(N^3)$——因为每一步的 Attention 复杂度是 $O(\text{step}^2)$,累加起来是 $1^2 + 2^2 + \ldots + N^2 = O(N^3)$。
这引出了 LLM 推理中最核心的优化:KV Cache。
8.2 Prefill 和 Decode 两阶段
LLM 推理实际上分为两个特性截然不同的阶段:
Prefill(预填充)阶段
处理用户输入的整个 prompt。所有输入 token 可以并行计算,一次前向传播就生成所有 token 的 K、V,并缓存起来。
1 | 输入: "请解释什么是注意力机制"(假设 10 个 token) |
Prefill 阶段的矩阵运算 batch 维度大($N$ 个 token 一起算),是典型的 Compute Bound(算力瓶颈)操作。它的耗时决定了 TTFT(Time To First Token,首 token 延迟)。
Decode(解码)阶段
逐个生成输出 token。每步只有 1 个新 token 的 Q 去和所有历史 K 做 Attention,新 token 的 K、V 追加到缓存中。
1 | Step 1: 1 个新 token 的 Q × 10 个历史 K → Attention → 生成 "注" |
Decode 阶段每步只有 1 个 token 的计算量,矩阵乘法退化为矩阵-向量乘,GPU 的算力远远用不满,大部分时间花在从 HBM 搬运 KV Cache 数据上。这是典型的 Memory Bound(带宽瓶颈)操作。它的耗时决定了 TPOT(Time Per Output Token,每 token 延迟)。
AI Infra 关联:Prefill 是 Compute Bound,Decode 是 Memory Bound——两个阶段的性能瓶颈截然不同,这直接催生了 Prefill/Decode 解耦 的系统架构(如 DistServe、Splitwise),把两种请求分配到不同的 GPU 池,各自针对性优化。
8.3 KV Cache 的由来
KV Cache 的核心思想很朴素:已经算过的 K 和 V 不需要重复计算。
在 Decode 阶段,每生成一个新 token,Self-Attention 需要计算新 token 的 Q 与所有历史 token 的 K 的内积。如果不做缓存,每一步都要重新对所有历史 token 做 QKV 投影——这些投影在之前的步骤中已经算过了,纯粹是浪费。
KV Cache 的做法是:把每一层、每一步算出的 K 和 V 缓存在 GPU 显存中。Decode 时,新 token 只需要计算自己的 Q、K、V,然后把新的 K、V 追加到缓存中,Attention 计算使用完整的缓存 K、V。
无 KV Cache(每步重新算所有 KV):Step $n$ 对 $n$ 个 token 全部重新计算 QKV,计算量 $O(n \cdot d^2)$;总计 $\sum_{n=1}^{N} n \cdot d^2 = O(N^2 \cdot d^2)$。
有 KV Cache(只算新 token 的 KV):Step $n$ 只计算 1 个新 token 的 QKV($O(d^2)$),Attention 用 1 个 Q 与 $n$ 个缓存 K 做内积($O(n \cdot d)$);总计 $O(N \cdot d^2 + N^2 \cdot d)$。
KV Cache 将 QKV 投影的总计算量从 $O(N^2 \cdot d^2)$ 降到了 $O(N \cdot d^2)$,代价是需要额外的显存来存储所有层、所有 token 的 K 和 V。
KV Cache 的显存开销:
以 LLaMA-2-7B 为例:
- 每个 token 需要缓存:2(K 和 V)x 32(层数)x 32(头数)x 128(head_dim)= 262,144 个元素
- FP16 下每个元素 2 Bytes → 每个 token 的 KV Cache = 512 KB
- 序列长度 4096 → 单请求 KV Cache = 4096 x 512 KB = 2 GB
- batch_size = 16 → 总 KV Cache = 16 x 2 GB = 32 GB
32 GB 的 KV Cache 在 80 GB 显存中已经占了 40%,加上模型参数 13.4 GB,留给其他开销的空间非常有限。这就是为什么 KV Cache 管理是推理优化的核心议题——PagedAttention(虚拟内存分页管理)、KV Cache 量化(用更低精度存储)、GQA(减少 KV 头数)等技术,都是在解决这个”显存刺客”的问题。
AI Infra 关联:KV Cache 是推理部署中最需要精细管理的资源。它引发的工程问题包括:显存碎片化(不同请求的序列长度不同,KV Cache 大小不一)、动态增长(Decode 过程中 KV Cache 持续增长)、多请求共享(系统 prompt 相同时的 Prefix Cache)。vLLM 的 PagedAttention、SGLang 的 RadixAttention 等推理引擎的核心创新,本质上都是在解决 KV Cache 的管理效率问题。
📝 总结
让我们回顾 Transformer Decoder Block 的完整结构,以及每个模块与 AI Infra 后续学习的关联:
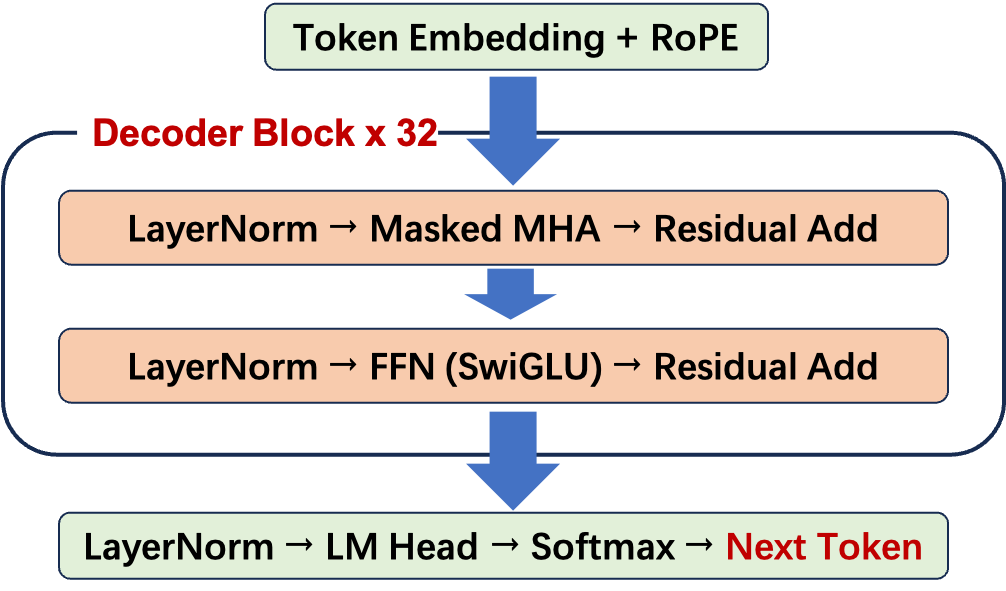
| 模块 | 核心计算 | 后续 AI Infra 关联 |
|---|---|---|
| Self-Attention | $QK^T$, Softmax, PV | FlashAttention(CUDA 优化)、KV Cache(推理)、张量并行沿头切分 |
| Multi-Head | 多头独立计算再拼接 | 张量并行(TP)的切分点、GQA/MQA(推理优化) |
| FFN (SwiGLU) | 三次大矩阵乘法 | 参数量大头、张量并行的另一个切分点、MoE 专家并行 |
| LayerNorm | 均值/方差归一化 | Kernel 融合优化、RMSNorm 简化 |
| 残差连接 | 逐元素加法 | 与 LayerNorm 融合、梯度流分析 |
| 位置编码 (RoPE) | 旋转 Q/K 向量 | 融合到 Attention kernel、长上下文扩展 |
| KV Cache | 缓存历史 K、V | PagedAttention、KV 量化、Prefix Cache |
| 自回归生成 | Prefill + Decode | Prefill/Decode 解耦、Speculative Decoding |
学习 Transformer 架构不是目的,而是起点。理解了”优化对象长什么样”之后,你会发现后续的每一项 AI Infra 技术都不再是空中楼阁——FlashAttention 在优化 3.3 节的 $O(N^2)$ 显存问题,张量并行在切分 3.4 节的多头结构和 4.2 节的 FFN 矩阵,KV Cache 管理在解决 8.3 节的显存开销问题。
🎯 自我检验清单
完成本文学习后,检验自己是否真正理解了 Transformer 架构:
- 能不看资料,在白板上画出一个完整的 Decoder Block 结构图(Masked Self-Attention → Add & Norm → FFN → Add & Norm),标注每一步的输入输出维度
- 能说清 Encoder-Decoder、Encoder-only、Decoder-only 三种架构变体的区别,以及为什么当前大模型普遍采用 Decoder-only
- 能说清 Q、K、V 三个矩阵各自的含义,以及 Attention 分数矩阵 $(N, N)$ 中每个元素的物理意义
- 能默写 Attention 完整公式 $\text{softmax}(QK^T / \sqrt{d_k}) \cdot V$,并解释为什么要除以 $\sqrt{d_k}$
- 能推导 Self-Attention 的 $O(N^2)$ 复杂度,并解释这如何催生了 FlashAttention
- 能解释 Multi-Head Attention 为什么适合张量并行切分,以及 GQA 相比 MHA 在 KV Cache 上的优势
- 能手算 LLaMA-2-7B 的总参数量(误差不超过 20%),并说清 FFN 和 Attention 的参数比例
- 能解释 Prefill 和 Decode 两阶段的计算特性差异(Compute Bound vs Memory Bound),以及 KV Cache 的由来
- 能估算给定配置下 KV Cache 的显存占用(如 7B 模型、4096 序列长度、batch_size=16 下约 32 GB)
📚 参考资料
论文
- Attention Is All You Need (Vaswani et al., 2017):https://arxiv.org/abs/1706.03762 – Transformer 原始论文,必读
- RoFormer: Enhanced Transformer with Rotary Position Embedding (Su et al., 2021):https://arxiv.org/abs/2104.09864 – RoPE 旋转位置编码
- GLU Variants Improve Transformer (Shazeer, 2020):https://arxiv.org/abs/2002.05202 – SwiGLU 等门控激活函数
- LLaMA: Open and Efficient Foundation Language Models (Touvron et al., 2023):https://arxiv.org/abs/2302.13971 – LLaMA 模型架构
- LLaMA 2: Open Foundation and Fine-Tuned Chat Models (Touvron et al., 2023):https://arxiv.org/abs/2307.09288 – LLaMA-2 技术报告
- FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness (Dao et al., 2022):https://arxiv.org/abs/2205.14135 – Memory-aware Attention 优化
- GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints (Ainslie et al., 2023):https://arxiv.org/abs/2305.13245 – Grouped-Query Attention
教程与博客
- The Illustrated Transformer (Jay Alammar):https://jalammar.github.io/illustrated-transformer/ – 图文并茂的 Transformer 入门
- Andrej Karpathy: Let’s build GPT from scratch:https://www.youtube.com/watch?v=kCc8FmEb1nY – 从零手写 GPT,代码级理解每个模块
- 3Blue1Brown: But what is a GPT:https://www.youtube.com/watch?v=wjZofJX0v4M – 直觉级理解 Transformer
- The Annotated Transformer (Harvard NLP):https://nlp.seas.harvard.edu/annotated-transformer/ – 论文逐行对应 PyTorch 实现